MAGI: MachineLearning Augmented Github Indexer
date
Apr 22, 2022
slug
MAGI-MachineLearning-Augmented-Github-Indexer
status
Published
summary
Magi, meaning "Wise Men", were priests in Zoroastrianism and the earlier religions of the western Iranians.
type
Post
tags
DataScience
DeepLearning
SemanticSearch
Python

TL;DR: MAGI is a semantic searcher that allows you to search over GitHub with natural language.
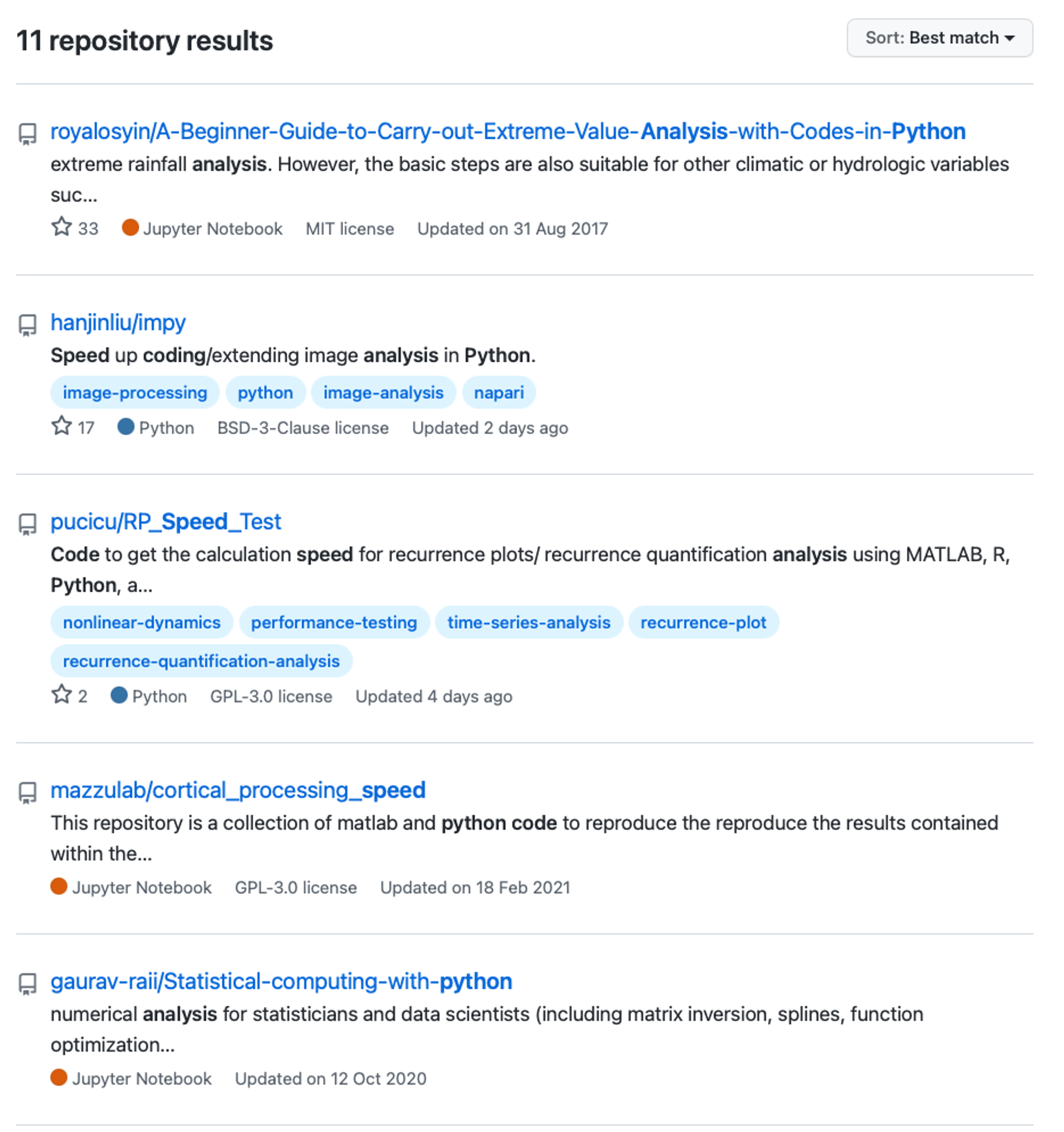
The good thing about open-source softwares is that developers nowadays hardly need to build the wheels again. If you need functionalities, simply search the corresponding package on GitHub - but this process could be tedious. Say I want to find a package to test my Python code speed, this is called a code profiler. But normally you would search “Test Python code speed”, and get this result:
This is why we developed MAGI, a semantic search engine for GitHub.
What is MAGI?
Magi, meaning "Wise Men", were priests in Zoroastrianism and the earlier religions of the western Iranians. In Evagelion, Magi System (マギ) are a trio of supercomputers designed by Dr.Naoko Akagi.
We hope that MAGI can work like its name, by intelligently understanding your query. You can try a demo of MAGI here:
When using MAGI, simply tell it what you want, and be specific. For example, ask for “find the slowest part of a Python program” instread of asking “code benchmark”; search for “visualize data, draw plots” instead of “visualize data”. The more verbose you are, the better MAGI responds. Here’s a list of querys FYI, if you don’t know where to start:
- Python easy cli interface
- Web archiving service
- Send notifications to mobile phone
- Extract articles from webpages
- Object detection models
Notice: This deployment runs with a starter plan on streamlit.io. Since the Transformers and PyTorch packages will take a considerable proportion of memory, it crashes sometimes. If you are really interested in playing with this demo and it crashes, you can always write to ycgu@umich.edu, I will reboot the demo ASAP. Also, I’ll write about how to run MAGI on your own device later.
How Does It Work?
MAGI’s structure looks like follow:
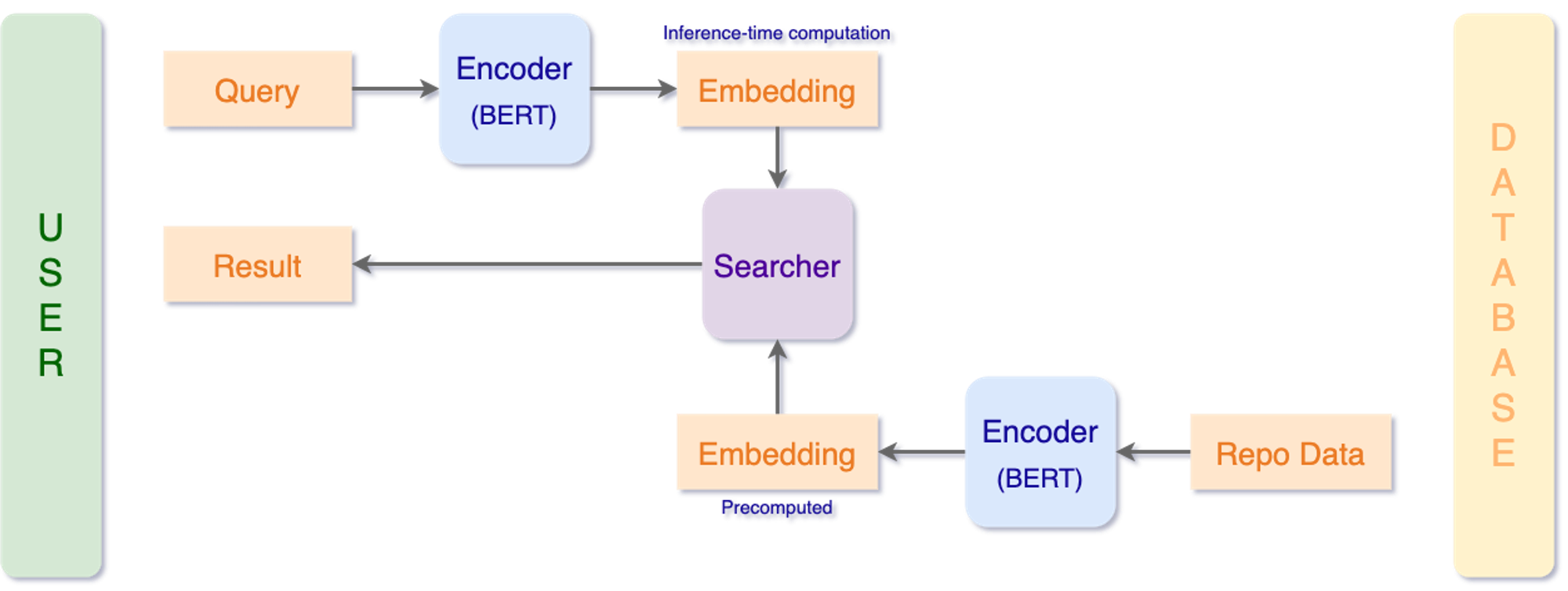
We’ve created a database of GitHub Python repositories with ≥ 100 stars, and projected them to a vector embeddings space using a SentenceBERT transformer. This model takes in a chunk of text, and spilts out a high-dimensional vector (usually 768). The more related two texts are, the closer their vector representation should be.
When you give a query to MAGI, your query will be projected to the same vector space, and MAGI uses a vector similarity search to retrieve repositories that matches your query best.
The database consists of two parts:
- Corpus from GitHub READMEs;
- Comments of this repositories on Hacker News, if there are any.
With this database, MAGI is able to understand your description of a package, and compare your description with the above data to decide which repositories are match.
MAGI is trained using a novel method called synthetic query generation. You can read more about this method here:

Basically, we use a T5 model that looks at some text, and raises questions on that text. For instance:

We generate 8 queries for each chunk of text in each repository. This gives ≥ 360,000 query-corpus pairs. We can then finetune our SentenceBERT model on top of these pairs. This methods allows us to run a NLP finetuing task without any data annotation.
With the data prepared, we train our SentenceBERT on this data for 3 epochs. After that, we use the trained model to cast our corpus to the embedding vector space. Since we have multiple corpus for each repository, we average their corresponding vector embeddings to get a final vector representation of that repository.
Benchmarks
Let’s compare this model with GitHub’s original search. For instance, we may search: “extract articles from web pages”, and MAGI will give the top 10 results as
codelucas/newspaper facebookresearch/DrQA dwyl/english-words sphinx-doc/sphinx yzhao062/anomaly-detection-resources ThioJoe/YT-Spammer-Purge instillai/machine-learning-course ml-tooling/best-of-ml-python lancopku/pkuseg-python SmirkCao/Lihang
Notice that the first result is exactly what we are looking for through this search - the one and only Python package which does that.
Where GitHub’s search simply fails:
We compiled 20 queries with their corresponding results as the benchmark, let’s compare mAP@10 of MAGI and GitHub search:
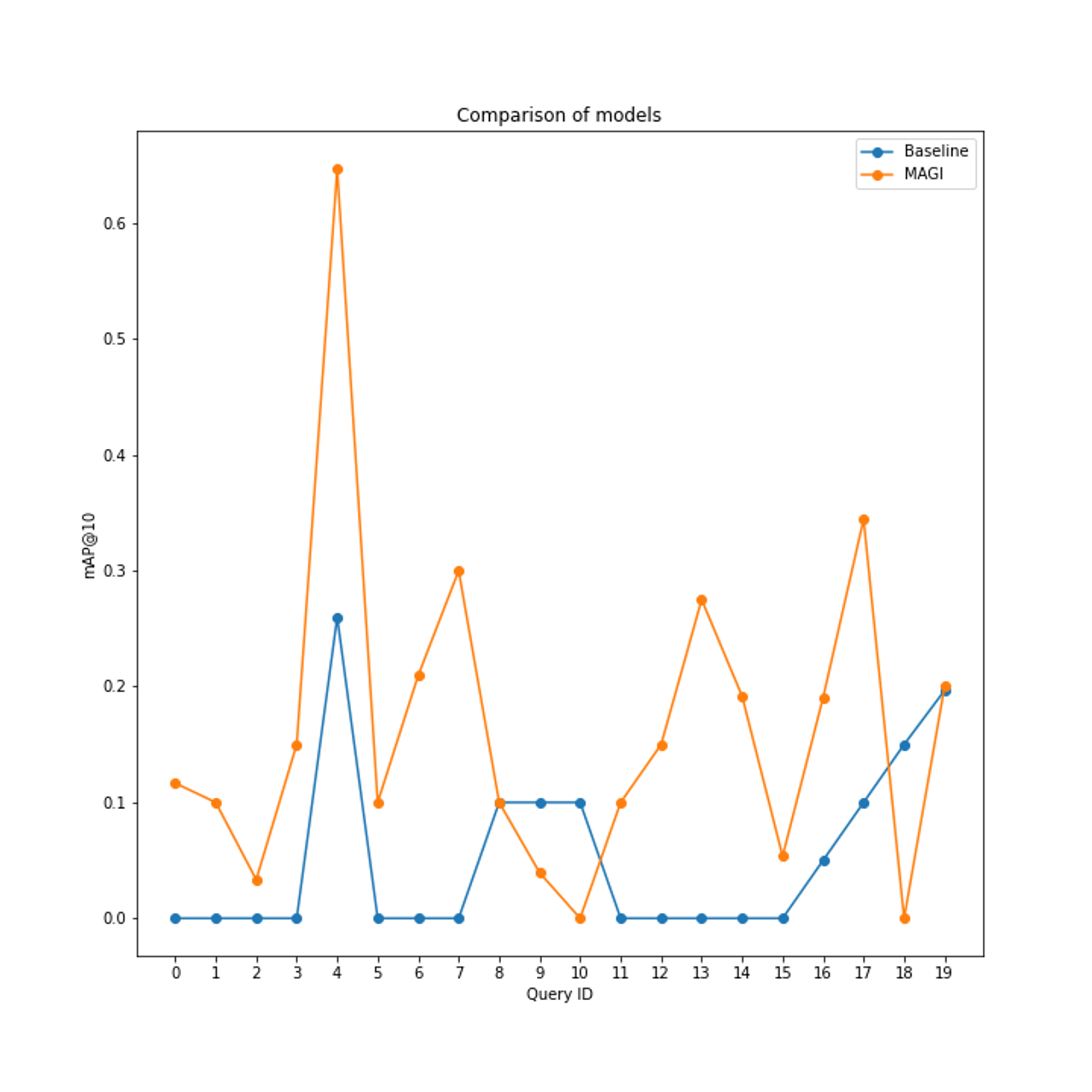
We can read from the figure that MAGI performs better than GitHub’s search on most cases, and has a mAP@10=0.1650. On the contrary, GitHub’s search only achieves mAP@10=0.0578.
Conclusion
MAGI utilizes transformer models to allow semantic search on GitHub repositories. We are keep working on MAGI to refine it for even better performance.
You can find MAGI’s source code at Enoch2090/MAGI.
Acknowledgements
Many thanks to IAmParadox, who generously shared the methodology of designing a context based search engine. The shared method provides us with plenty insights. You should check out their work IAmPara0x/Yuno, which is a context based search engine for anime.