DARWIN: A Natural Language Car Information Search Engine
date
Dec 14, 2021
slug
darwin-a-natural-language-car-information-search-engine
status
Published
summary
DARWIN stands for Documented Automobile Retrieval system With Information Neural network.
type
Post
tags
DataScience
DeepLearning
Python
DARWIN stands for Documented Automobile Retrieval system With Information Neural network.
Estimated Read time: 8 minutes
TL;DR: We developed a second-hand car search engine using dependency matching and RNN network along with a modified BM25 ranker. Using this combination of techniques, the mAP of search results on the query set is almost doubled. The Github homepage for the project can be found at

And a live demo is deployed at

Introduction
Current car dealer websites are mostly filter-based, which means people must decide on a series of parameters like mileage, drivetrain, make and engine before being presented with choices. However, the fact is most people have no concept of these values, especially for those buying a car for the first time. A descriptive sentence that implicitly conveys the needs of a car buyer is more common in the real world, for instance, “I want a small car which supports Apple CarPlay”, etc.
According to our investigation, there are currently no such system on the internet. Darwin is therefore proposed and implemented. Our system is acting like a sales manager focusing on such fuzzy search to better help nonprofessional car buyers choose the best deal according to their needs.
Data
We developed a scraper script that scrapes data from Cars.com. The website maintains a relatively well- structured HTML code, so it is not difficult to extract all the features we need from different locations on the page. To achieve this, we first get the link to each car's unique page using
beautifulsoup4. Here's the code:from bs4 import BeautifulSoup import requests from tqdm import * import json import os base = "https://www.cars.com" if os.path.exists("links.json"): with open("links.json", "r") as f: links = json.load(f) else: links = [] for i in trange(100): url = f"{base}/shopping/results/?page={i}&page_size=100&list_price_max=&makes[]=&maximum_distance=all&models[]=&stock_type=all&zip=48113" cars_raw = BeautifulSoup(requests.get(url).text) cards = cars_raw.find_all("div", {"class": "vehicle-card"}) links += [base+c.find_next()["href"] for c in cards]
Next, we traverse each link and download the details of the car using a similar method. See

for the entire code.
Totally 9,975 second-hand cars are collected as dataset, and after cleaning, there were about 9,200 remain. Some statistics of the dataset:

Methods
Darwin is a combination of natural language processing techniques and information retrieval techniques. The system accepts natural-language-like inputs. Mainly three techniques are used to ensure this, and the overall architecture of Darwin's pipeline is:

Let's go over the pipeline one by one.
1. Dependency Match
To handle natural language inputs, the input query is first passed through a dependency parser. When describing a certain features of a car, it is common that certain short adjective-noun phrases are used. The purpose of dependency match is to capture these phrases in the input query.
For example, if we query "I want a car wit strong horsepower". The dependency tree is then something like:
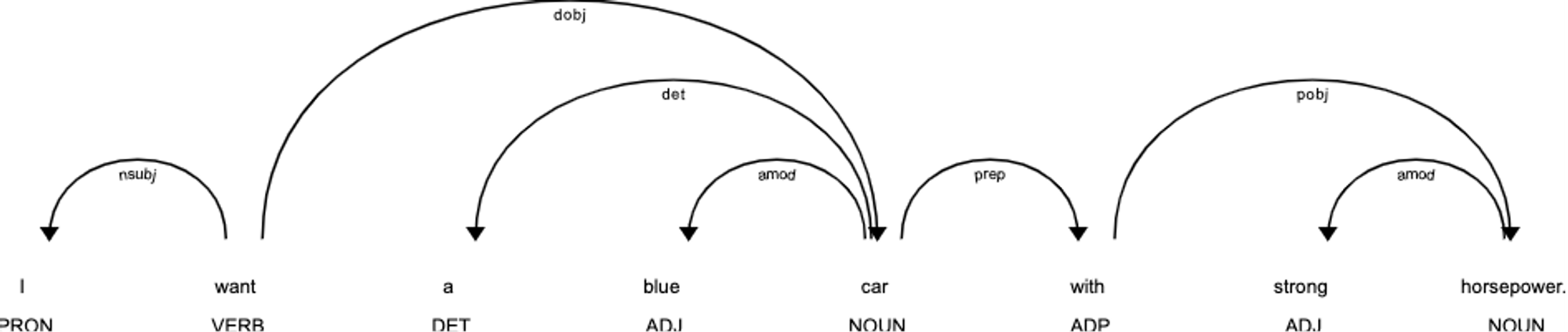
The word ”want” only has outgoing arcs, therefore it is the root of the dependency tree. By traversing through the arcs, the tree structure can be obtained. For example, one of our specified pattern looks for
pobj after amod. In spaCy, we can use the codeimport spacy from spacy.matcher import DependencyMatcher nlp = spacy.load('en_core_web_lg') patterns = [[ {'RIGHT_ID': 'p_object', 'RIGHT_ATTRS': {'DEP': {"IN": 'pobj'}}}, {'LEFT_ID': 'p_object', 'REL_OP': '>', 'RIGHT_ID': 'p_object_mod', 'RIGHT_ATTRS': {'DEP': {"IN": 'amod'}}}, ]] doc = nlp("I want a car wit strong horsepower.") matcher = DependencyMatcher(vocab=nlp.vocab) dep_matches = matcher(doc)
And it gives a list of indexes to the matches in the document. By creating a set of patterns, we can capture more than 80% of the features in a query. See

for the full code. Also, if you are interested in dependency matches in spaCy, we recommend to read this great article:
2. Feature Classification using RNN
After the features are extracted, to better use these features, we use a recurrent neural network (RNN) to figure out which feature class does this feature belong to. Limited to the length of this article - we will omit the introduction to RNNs. If you are not familiar with RNNs, refer to this page for everything you need to know:

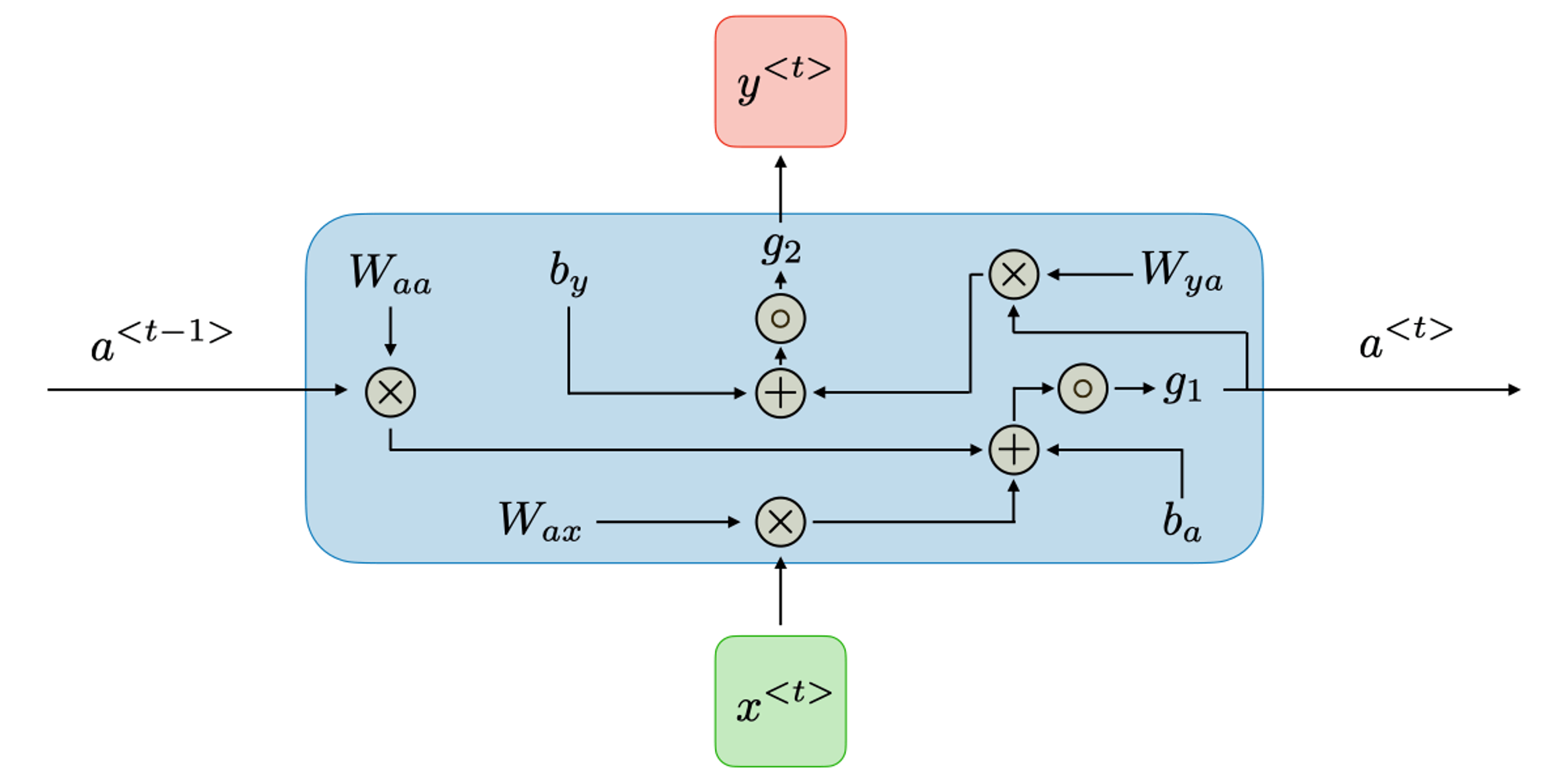
We choose a many-to-one structure. The hidden size of the network is set to be 128 based on the prepared training set. The activation function for each hidden state is linear. A
LogSoftMax layer follows the output to generate probabilties of each class. For simplicity, the RNN is designed as a character-level network. The input is a character set in one-hot encoding of the feature. We choose 52 English characters adding a few puncts, in total 57 characters as the character set, so each line of input is a 1 × 57 tensor. And the output is the probabiliity of each class. The definition of the RNN is here (it basically follows a standard PyTorch RNN definition) - but you can safely skip it:
import torch import torch.nn as nn class RNN(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(RNN, self).__init__() self.hidden_size = hidden_size self.i2h = nn.Linear(input_size + hidden_size, hidden_size) self.i2o = nn.Linear(input_size + hidden_size, output_size) self.softmax = nn.LogSoftmax(dim=1) def forward(self, input, hidden): combined = torch.cat((input, hidden), 1) hidden = self.i2h(combined) output = self.i2o(combined) output = self.softmax(output) return output, hidden def initHidden(self): return torch.zeros(1, self.hidden_size)
To make the process faster, we took a different approach than manually annotating a dataset. The main corpuses used for the training are the posts from r/askcarsales on Reddit. We made an assumption that each input feature consists of two words, a noun with a adjective modifying it. With the assumption, we extract all two-word patterns either by fixing the noun or fixing the adjective. The extracted patterns are assigned to a class according to the fixed term. This consists of our dataset, with approximately 9,000 rows of data and four classes. Here's some pattern and sample matches:

And, code for these works can be find here:

The code for training mostly comes from the following tuorial:

We bootstrap samples from this dataset iteratively to train the network. The loss looks like:
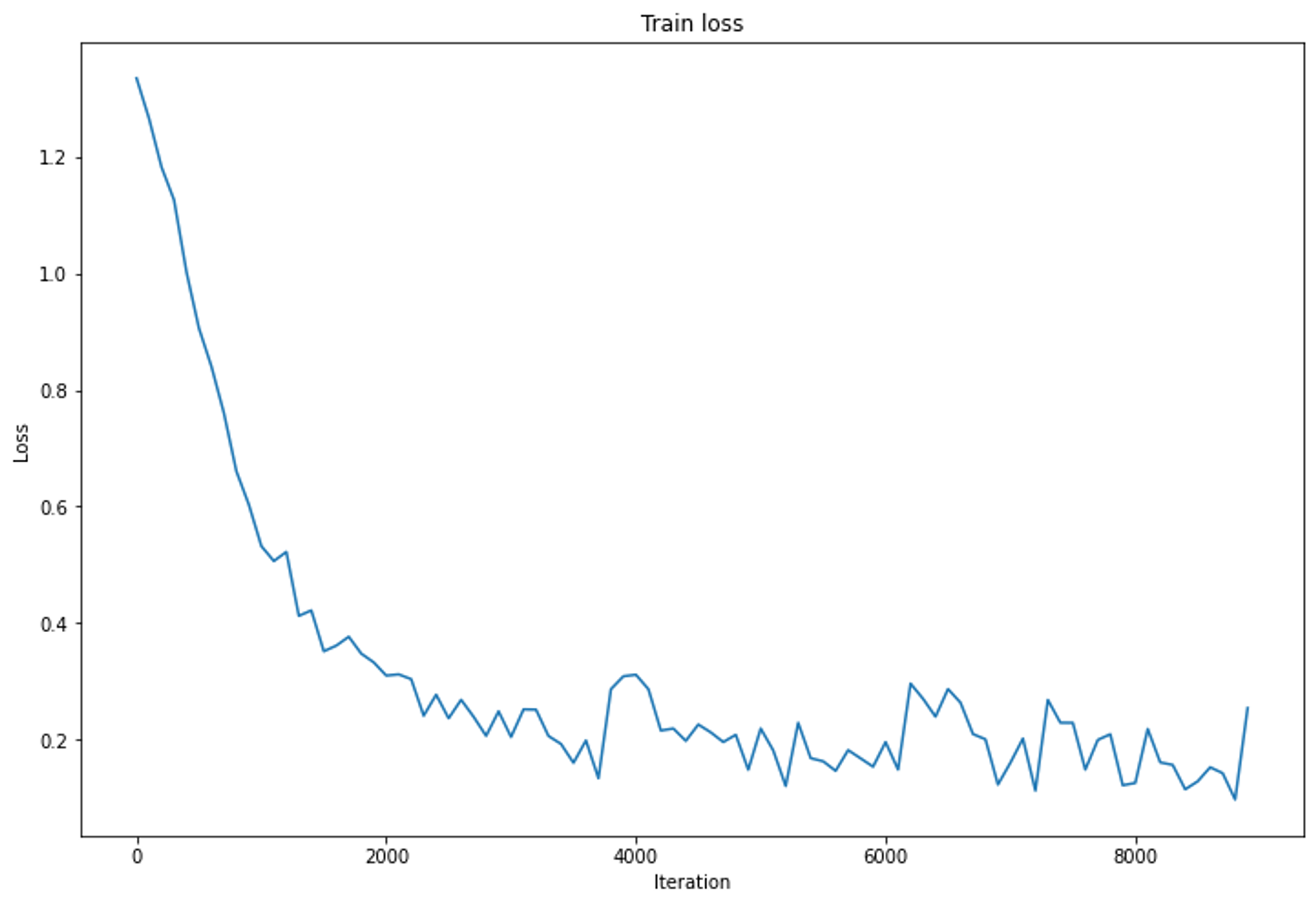
And the final confusion matrix shows that the power and configuration classes are well-fitted, while the price and exterior classes are sometimes confused.
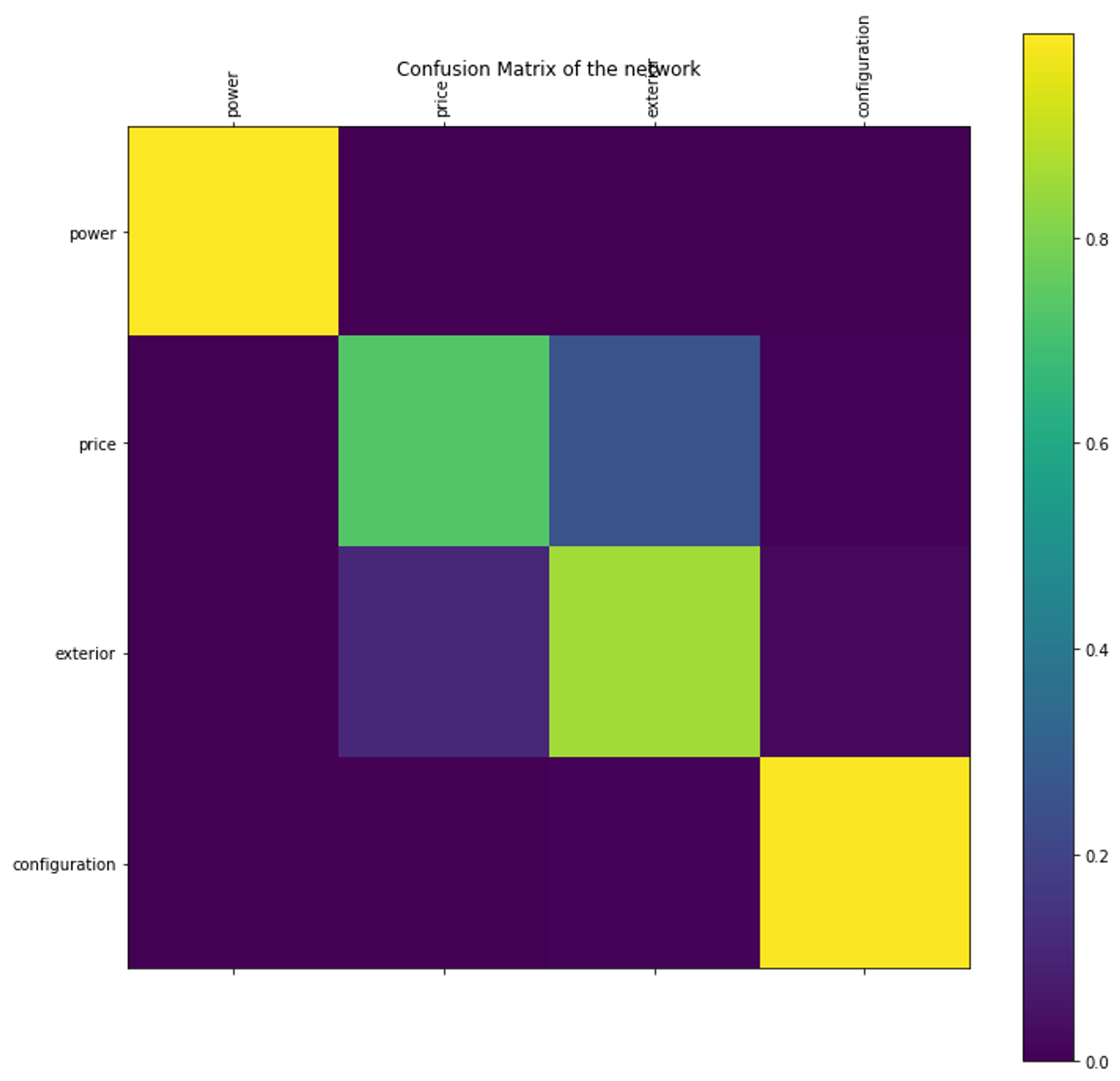
This is understandable, because both classes would have phrases with an adjective modifying the word ”car”, ”SUV”, ”sedan”, etc. This will disturb the network. But anyway, it is pretty good for a network based on unsupervised samples generated in 5 minutes!
3. Feature Search (Ranking)
A BM25 ranking is used with the score equal to
Check

for everything you need to know about BM25. We use the tuned hyperparameter , and here.
In addition to this BM25 ranking, we also compare the extracted query features to the feature set of current document to give extra credits to the document if it satisfies the conditions. For seven logic values on configurations and two numerical values on power, we give 0.1 extra score if the current document conforms to query features, while for features like car make, drive train, exterior colorand price, we reward the document 0.4 extra points.
Also, to judge whether our features from neural network are consistant to the ones in current document, we divide the work into two situations:
- Simple features. This includes exterior color, car make, etc. that can be represented by simple and accurate words.
- Extent features. This includes power, configurations that comes with various adjectives before them.
For simple features, we simply match them through finding the intersection between current document’s feature set and certain key-value pairs in the output of neural network. If there exists intersection, we will give additional score to the document due to its relevance to the query in terms of feature. For extent features, we roughly define several mappings from common vocabular- ies/numerical values to three levels of extent: cheap/low, moderate/average, and expensive/high. We first match keywords in the output of neural network to classify them into three categories, then we manually define threshold for numerical values so as to judge whether current document’s feature falls into the same category. Finally we can decide whether to give extra score to the document based on the classification result for extent features.
4. Interface!
For deployment, we designed an interface using the package Streamlit. Users can use this web interface like using an ordinary search engine. Here's how it looks like -
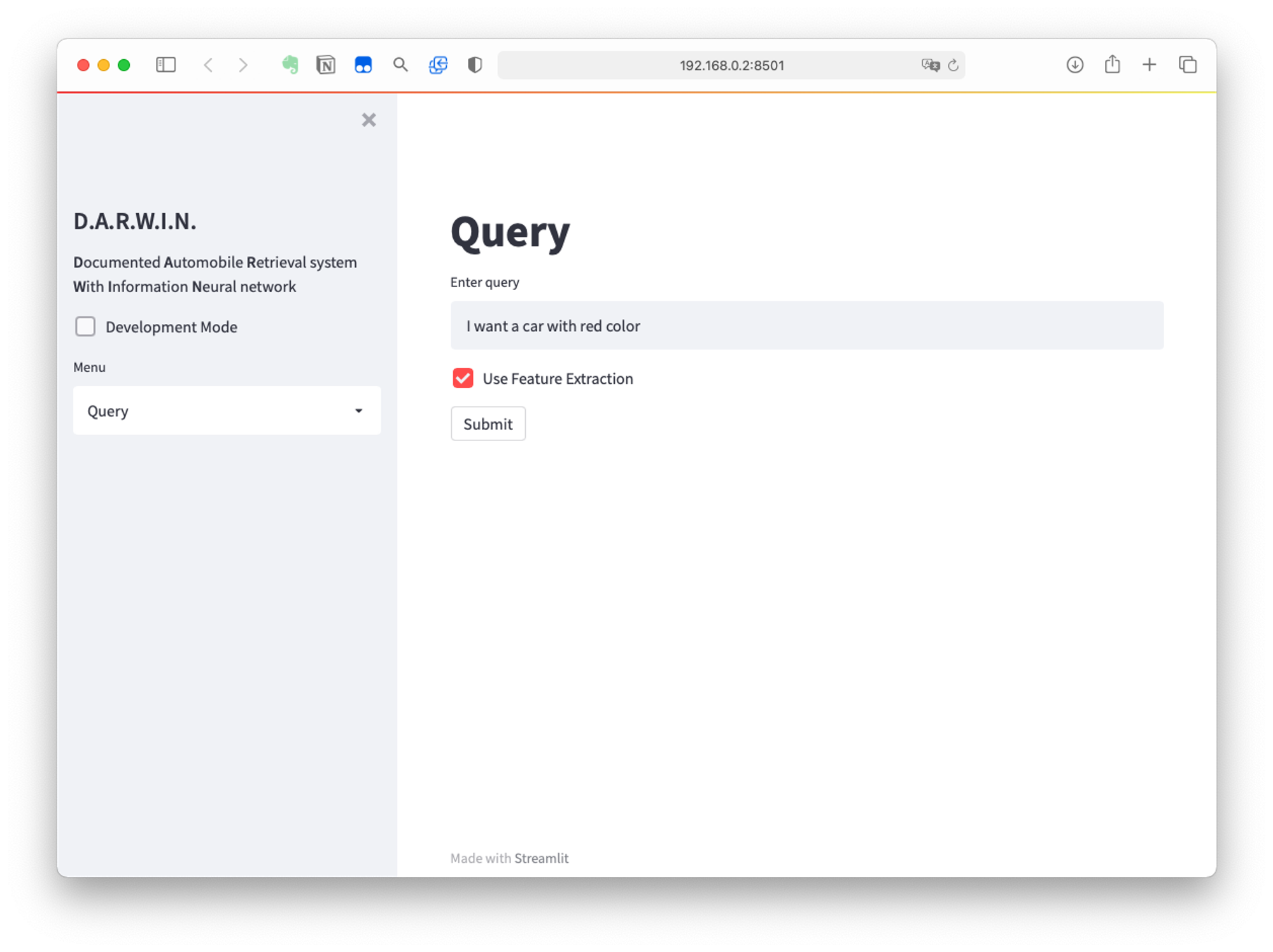
The interface is now avaliable on Heroku. To maintain performance of the backend, two levels of cache are used across objects. The first level of cache an experimental primitive decorator of Streamlit. In the entire lifecycle of a Streamlit app, the unique objects in the pipeline are shared across different sessions. Hence only the first access to the object requires to initialize it.
The second level of cache is the data interaction with the objects. For the time-consuming interactions such as feature classification, a PipelineCache object is prepared to store all existent input-output pairs. If the input exists in the cache, it will not be processed by that stage again, but instead the corresponding output in the cache will be directly returned.
Evaluation and Discussions
For evaluation, we used Pyserini to index and run a BM25 base line first. The features we extracted are concated into a single string as the document. The querys are searched on this document, we show a part of the results here:
("..." represents features omitted here due to page limits.) 1 - I want a red car with heated seats. > doc 3064 - 2008 Chevrolet Corvette Indy Pace Car, 19995, Red, ... > doc 1821 - 2011 Dodge Ram 1500 20 WHEELS SEATS PKG, 17985, Gray, ... > doc 3085 - 2004 Lincoln Town Car Ultimate L, 7995, Gold, ... 2 - I want a blue car with CarPlay. > doc 3064 - 2008 Chevrolet Corvette Indy Pace Car, 19995, Red, ... > doc 3085 - 2004 Lincoln Town Car Ultimate L, 7995, Gold, ... > doc 3102 - 2008 BMW 128 i, 8900, Blue, ...
To evaluate the effectiveness of this baseline, the queried results are manually marked as rele- vant/irrelavant. The web interface has incorporated such feature. Then, we calculate the mAP of the baseline. We use the same procedure for the enhanced model too.
The avaerge MAP for baseline is 0.24 while our enhanced model delivers a 0.47 average MAP. The destribution is:
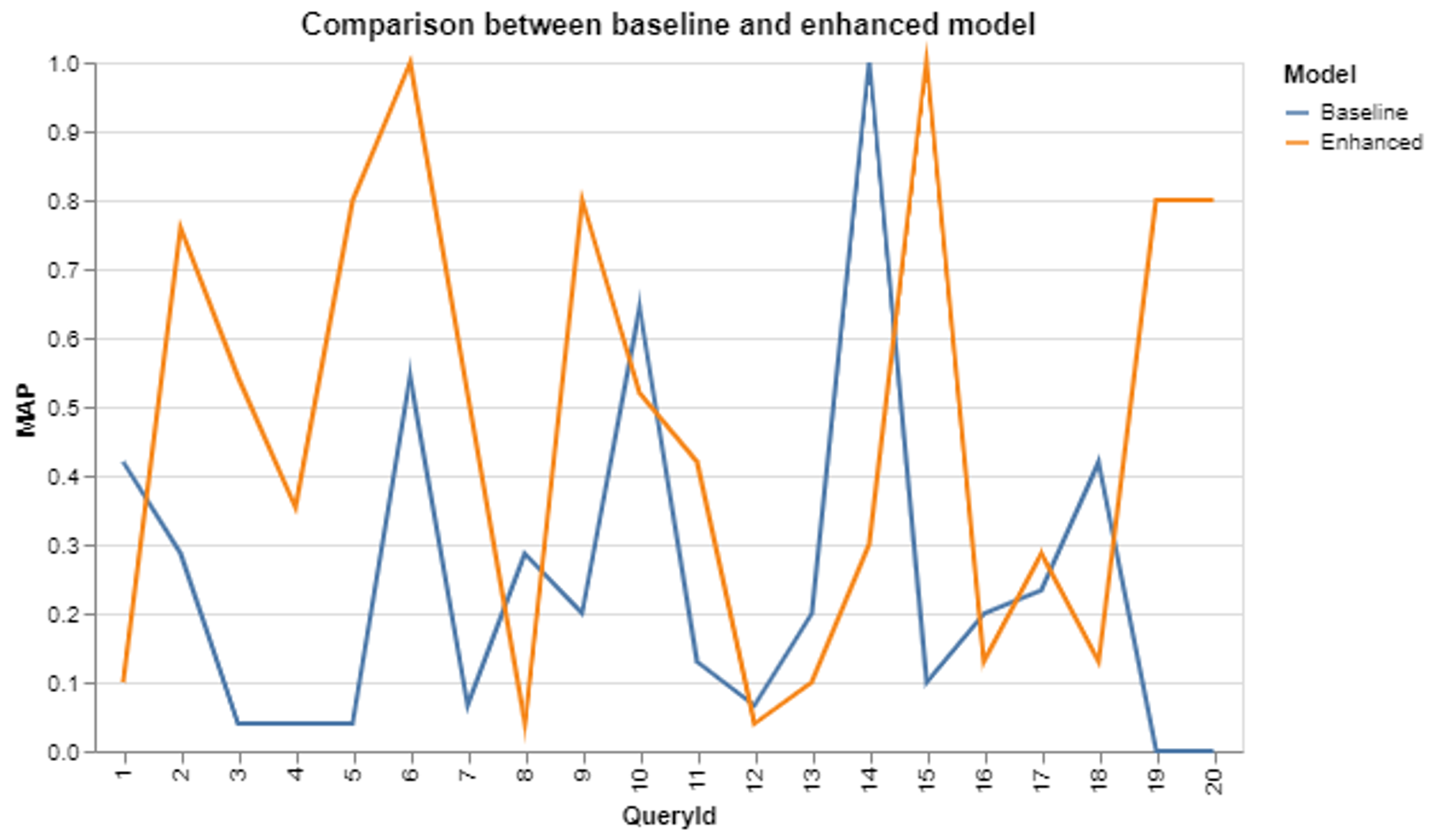
From the graph we can see in over half of the queries, the enhanced model performs better than the baseline. By checking the content of queries, we find our proposed model has high accuracy in matching the color, power, price, and drivetrain.
Our approach makes a 92% improvement (0.47) in terms of average MAP across 20 example queries against the baseline (0.24), which is out of our original expectation. Our model does well in extracting salient features like drivetrain, exterior color, and make because they are often single attribute words before the keyword ”car”, we use regular expression to filter out these features and set as input of our neural network model. Our solution also does well in selecting the proper price and determining the scale of feature (high/low power, poor/rich configuration), which is achieved by the extent word bank created by our own. We figure out a set of adjectives people always use in daily life and use them to map a wide range of query terms to three categories, which yields a good result for most cases.
However, the weakness of our solution is magnified if the sequence of words in the query is changed, or rare words and numerical values are included, or a more narrative tone is used together with too much details. For example, the retrieved results demonstrate high randomness for the query ”I am a student searching for a light-color sedan capable of driving in snowy days”. Our model is still at the level of understanding word-level meanings but not the implications behind words. Moreover, we are mostly focusing on a few basic queries and make a small number of annotations to support it, which is far from constructing a huge dataset for training a robust model.
What's Next?
First, the original code has already been open-sourced on Github. The interface is also avaliable to be used. Check here:

You can run
streamlit run interface.py under the interface directory to start it. We will do some small adjustments, add dependency specifications and a detailed README. Next, here's a list of works that can be done:
- The feature extraction module can have more parallel rules to capture more kinds of two-word, even three-word phrases.
- The feature classification network should be retrained with better data and a valid test set to prevent overfitting. Given enough time and human resource, a manually annotated dataset can greatly improve the performance of the RNN.
- The first level cache hasn’t been tested to be thread-safe. When accessed by multiple users at the same time, problems may occur. This needs further testing.
- Each uncached query takes around 5 seconds on our dataset. This can further be improved by pre-calculated cache and multiprocessing.
- ...
Conclusion
That's all about Darwin. It's been fun developing such a small project, and we've defintely learned a lot tricks (especially NLP tricks) in that process. We hope that through this post you can also learn these tricks (or you probably already know them?). But with or without those tricks, Darwin is still a primitive demo, and has a long way to go.
What if I am interested in making a project like Darwin?
Take SI650 at UMICH. Syllabus here (may subject to change):
Finally... Acknowledements
Our thanks to Darwin Marsh, this project wouldn’t be proposed were it not for the Ford that he sold to us. It was a perfect car for us and we had great times.

If you are interested in buying second-handed cars around Michigan, take a look at Darwin's page:


But just ignore his design.