gem5使用指南
date
Jul 20, 2022
slug
gem5-manual
status
Published
summary
gem5 模拟器是一个模块化的计算机架构模拟器。
type
Post
tags
ComputerScience
Linux
指南
快速开始配置环境编译 gem5运行 Demo添加一个分支预测器可能遇到的问题Could not make proto path relative‘python3\r’: No such file or directory

gem5 模拟器是一个模块化的计算机架构模拟器,用来做计算机架构的模拟和测试。本文参考 gem5 的部分官方文档和 learning gem5 一书,简单介绍了 gem5 从编译到使用的方法;并且整理了在 gem5 中编写一个新的分支预测器的详细流程。
这篇笔记是在做毕设的期间写的,用的部分说明图是撰写论文的时候自己画的。参考:

快速开始
gem5 在 Ubuntu 18.04 和 Ubuntu 20.04 均通过测试,在 macOS 上也基本能使用,但是不支持 Windows。据我所知在 macOS 上可能会遇到和 clang 相关的问题,但因为我目前主力机是 Windows,所以具体细节如果以后有机会再补充。
如果你用的是 Windows 系统,可以用 Docker 或 WSL 来运行 gem5。下面以 wsl 为例,首先从微软商店安装 wsl 2 的Ubuntu 20.04。建议不要用 wsl 1 的虚拟机,虚拟化不充分有可能会带来问题。建议不要放在 wsl 的
/mnt 目录下,因为 wsl 2 对挂载 Windows 盘符的文件访问非常慢。配置环境
首先装依赖。SCons 是用来编译 gem5 的工具,必装;protobuf、Boost 等是可选的。
在没有安装任何依赖的系统里,可以直接使用以下命令安装所有依赖。
Ubuntu 20.04:
sudo apt install build-essential git m4 scons zlib1g zlib1g-dev \ libprotobuf-dev protobuf-compiler libprotoc-dev libgoogle-perftools-dev \ python3-dev python-is-python3 libboost-all-dev pkg-config
Ubuntu 18.04:
sudo apt install build-essential git m4 scons zlib1g zlib1g-dev \ libprotobuf-dev protobuf-compiler libprotoc-dev libgoogle-perftools-dev \ python3-dev python libboost-all-dev pkg-config
编译 gem5
gem 5 的官方文档介绍了编译的方法,可以参考阅读:

这里简单介绍一下如何编译。gem5 的代码中包含了多种架构的实现,编译的过程就是指定某个架构和对应的版本,得到一个对应的二进制文件。
首先从官方 git 获取源码:
git clone https://gem5.googlesource.com/public/gem5 cd gem5
在 gem5 目录下调用 SCons 进行编译:
scons build/{ISA}/gem5.{variant} -j {cpus}
这里
{ISA} 代表目标指令集架构,可选值包括 ARM、MIPS、X86、RISCV、SPARC 等。{variant} 代表编译的变种,不同的变种功能略有不同:debug:关闭了编译器优化的版本,运行速度会明显变慢,但是更方便搭配 gdb 和 valgrind 来 debug。
opt:启用编译器优化,但是保留了一些 debug 功能,一般都采用这个版本。
fast:启用编译器优化,并且关闭所有 debug 功能,速度最快。
如果没有什么特殊需求,使用
opt 变种即可。这里和下文均以 X86 架构为例继续,那么我们的编译命令为:scons build/X86/gem5.opt -j 4
运行 Demo
在
gem5/configs 下面有很多示例的代码。这里以幽灵攻击为 demo,这也是我最早接触 gem5 时跑的模拟(EECS4700J Lab 6)。参考:
首先准备一份
spectre.c 的代码。上面那篇论文的附录里有,或者在 GitHub 上也有很多实现,例如 Badel2/spectre.c。把这个文件放在一个方便调用的目录里,我就直接放在 gem5 目录下了。用 gcc 编译一下:gcc ./spectre.c -o ./spectre
编译前建议在 Windows 安全中心关闭”病毒和威胁防护“设置下的”实时保护“,否则编译出来的文件可能会直接被 Windows删除。
我们直接修改
gem5/configs/learning_gem5/part1 下面的例子来运行这个 demo。在 two_level.py 中,找到system.cpu = TimingSimpleCPU()
改成
system.cpu = DerivO3CPU(branchPred=LTAGE())
在
gem5 目录下运行:./build/X86/gem5.opt ./configs/learning_gem5/part1/two_level.py ./spectre
看到如下输出即表明运行成功。
添加一个分支预测器
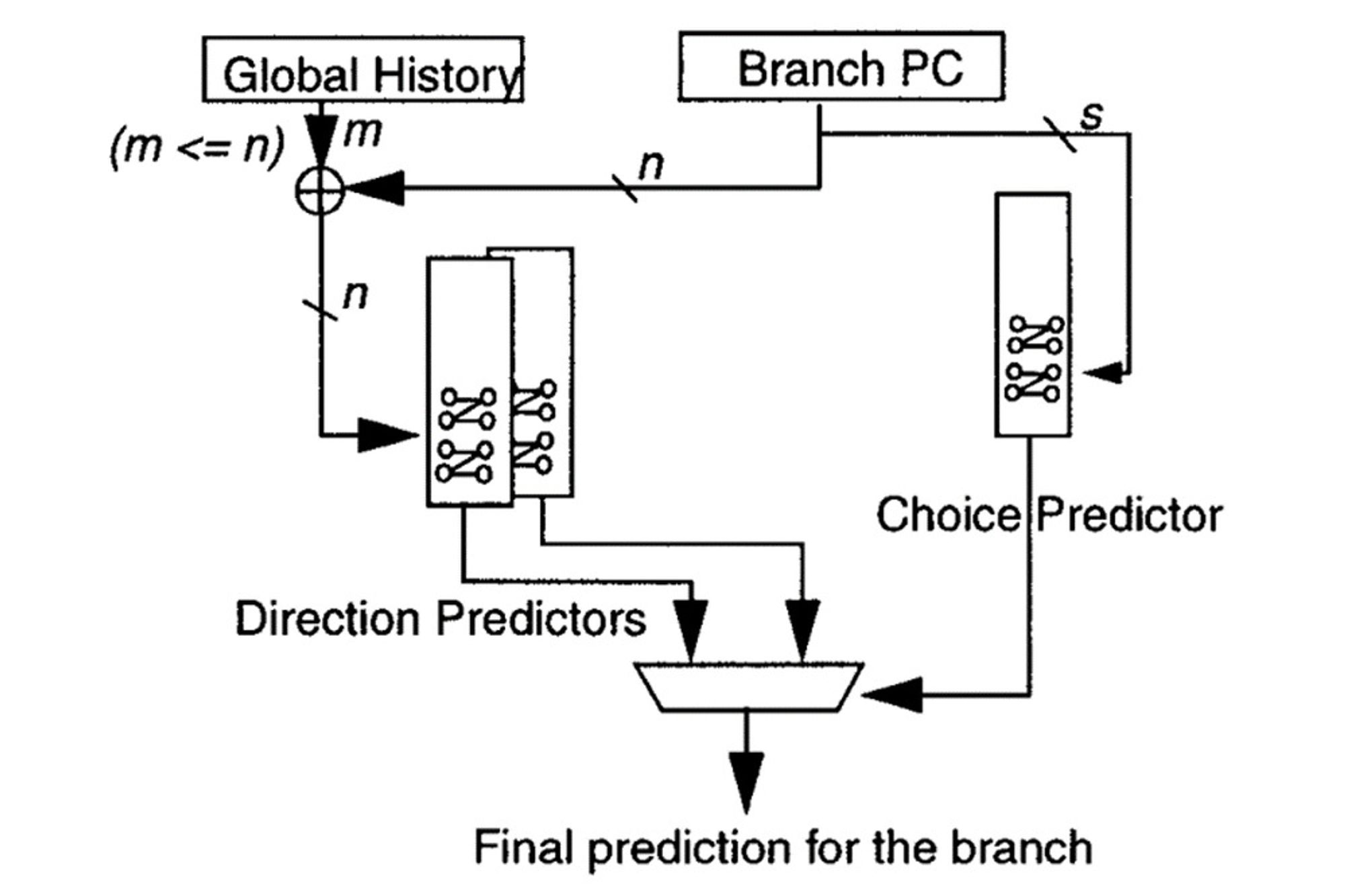
gem5 中包含以下的分支预测器:
名字 | 论文/出处 | 代码位置 |
BiModeBP | bi_mode.cc | |
LocalBP | N/A | 2bit_local.cc |
LoopPredictor | N/A | loop_predictor.cc |
TAGE | tage.cc | |
LTAGE | ltage.cc | |
TournamentBP | N/A | tournament.cc |
MultiperspectivePerceptron | multiperspective_perceptron.cc |
所有其它 BP 都是这些的拓展(组合,例如
MPP_TAGE;衍生,例如 TAGE_SC_L_64KB;等等)。对于这张表里的大部分 BP,可以在 Historical Study of the Development of Branch Predictors 一文中找到简单的描述。表中大部分 BP 都是有一个中间的抽象类用作继承的,例如 BranchPredictor → TAGE (Abstract) → TAGE_SC_L_64KB。如果直接添加一个 BP,相关代码建议直接参考 BiModeBP 的代码,这个类是直接继承自 BranchPredictor 的。我们先来看看 gem5 的结构。
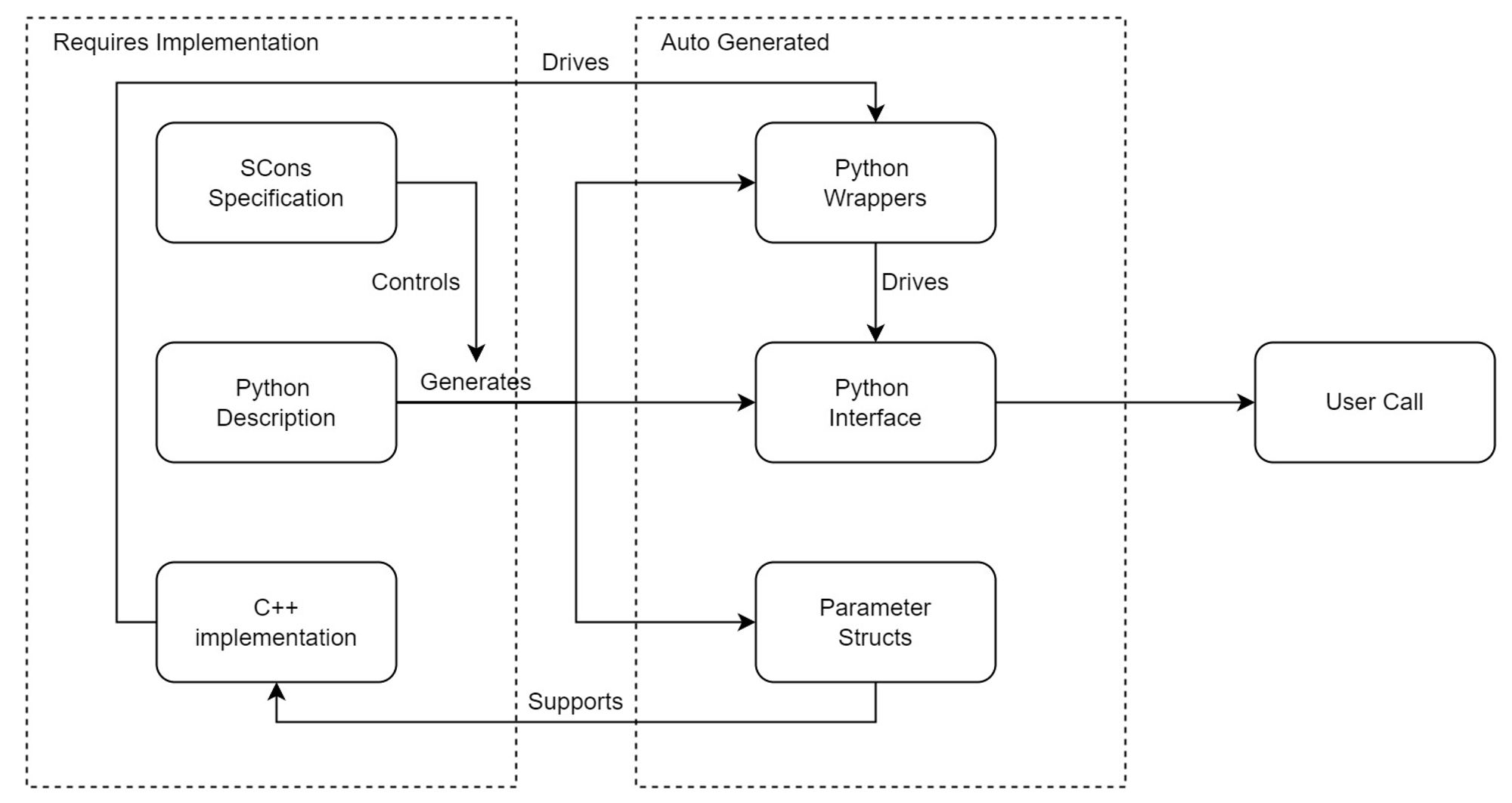
在 gem5 中,为了新增一个待模拟的模块,我们要实现三个部分:模块的 SCons 编译脚本,模块的 Python 描述,以及模块的 C++实现。通过 Python 描述,gem5 可以自动生成对应的 wrapper 和 parameter 头文件,用于模拟。
要向 gem5 添加一个新的 SimObject,分为以下几步。
首先,我们来实现模块的 Python 描述。创建一个 Python 脚本,通过继承的方式创建这个 SimObject 的类。因为是添加一个新的 BP,所以可以直接加在
gem5/src/cpu/pred/BranchPredictor.py 里面:class MyBP(BranchPredictor): type = 'MyBP' cxx_class = 'gem5::branch_prediction::MyBP' cxx_header = "cpu/pred/my_bp.hh"
其次是在 C++ 中编写对应的 SimObject。Learning gem5 中没有对 BP 的介绍,通过阅读 gem5 的 API 文档来确认接口。我们要重写这个页面里标记为 virtual 的方法。

uncondBranch
virtual void uncondBranch (ThreadID tid, Addr pc, void *&bp_history)=0
在 unconditional branch 时调用,大部分 BP 在这个地方应该做的事情是更新全局的记录,把这个 PC 记作 taken。
squash
virtual void squash (ThreadID tid, void *bp_history)=0
在有错误预测时调用。这个方法应该做的是重置这次错误预测带来的所有后果,比如它后面跟的指令导致 BP 内部的计数器、寄存器等发生的变化。在
update 方法中应该设法保存一份这些信息的备份,在 squash 时就能直接回退到备份。lookup
virtual bool lookup (ThreadID tid, Addr instPC, void *&bp_history)=0
输入一个 PC 地址,返回这个 PC 地址是否预测为 taken。这一步也会去更新全局历史、局部历史等寄存器,尽管这个 PC 地址到底有没有 taken 还没有被计算出来,这个更新的目的在于让这条指令后面跟的指令能够正确使用寄存器里的历史记录。如果出错,会由
squash 方法去恢复备份。btbUpdate
virtual void btbUpdate (ThreadID tid, Addr instPC, void *&bp_history)=0
在 branch target buffer (BTB) 遇到 miss 时调用。这种情况下,即使 BP 成功预测了这个分支时 taken/not taken,也没法给出下一个 PC 跳到哪里。这种情况下,这个分支会被当作 not taken 处理,然后通过
btbUpdate 这个方法去清除 lookup 方法带来的错误结果。update
virtual void update (ThreadID tid, Addr instPC, bool taken, void *bp_history, bool squashed)=0
给定一个 PC 是否 taken,更新各种寄存器里的值。
gem5 的分支预测器的执行顺序,并没有详细的说明文档。在做毕设的时候我们做了一些实验来确认这个执行顺序,此处简要介绍一下。假定 CPU 的 IF stage 现在碰上了一条分支指令 B1,然后给出了 B1 的预测结果。顺着这个结果,CPU 继续向下执行,在那条路径上很可能还会碰上更多的分支指令 B2,B3,…,Bx,对于每一条指令,gem5 都会调用分支预测器去检查结果。过了一段时间后,B1 这条指令在 CPU 中终于计算出了真正的结果。此时具体过去了几个周期取决于 CPU 的 ISA 和架构。例如 RISC-V 的五阶段流水线就是两条指令;而 O3 乱序执行的 X86,视架构不同可以达到几十条。这其中可能有十几条的分支指令。B1 的结果出来后,CPU 就会考虑是不是要 squash 流水线了,此时gem5 中有两种可能:
- B1 的预测是正确的。
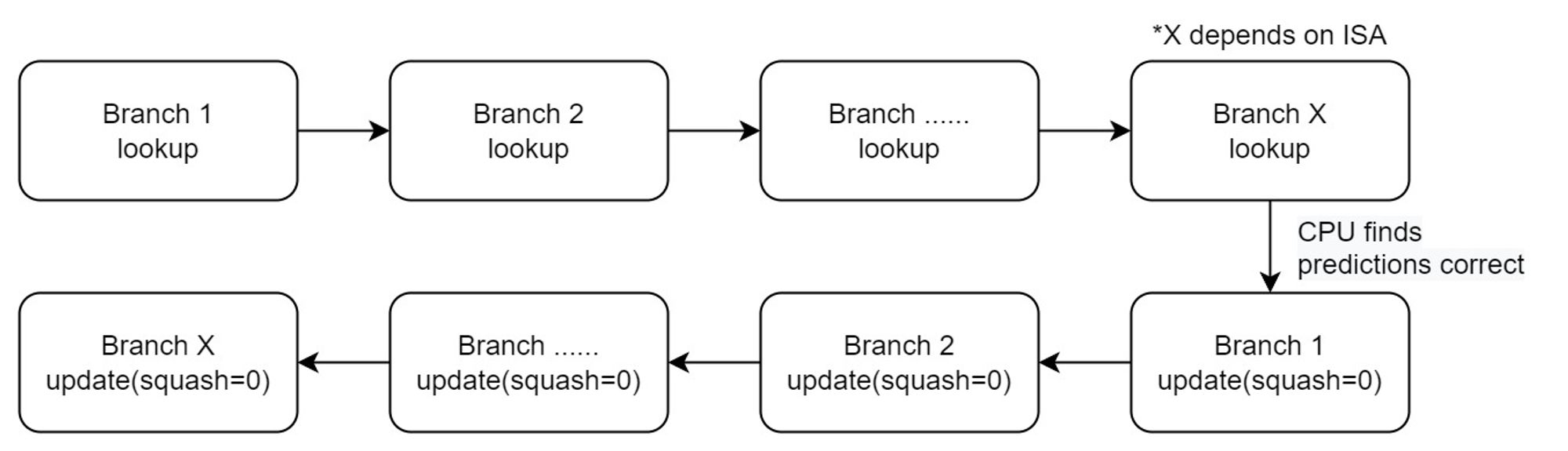
此时 gem5 会在这个周期里,对 B1 调用
update(squash=false)。随后 gem5 继续执行,直到 B2 的真正结果被计算出来,然后在那个周期里,对 B2 再调用 update(squash=false),依此类推。- B1 的预测是错误的。
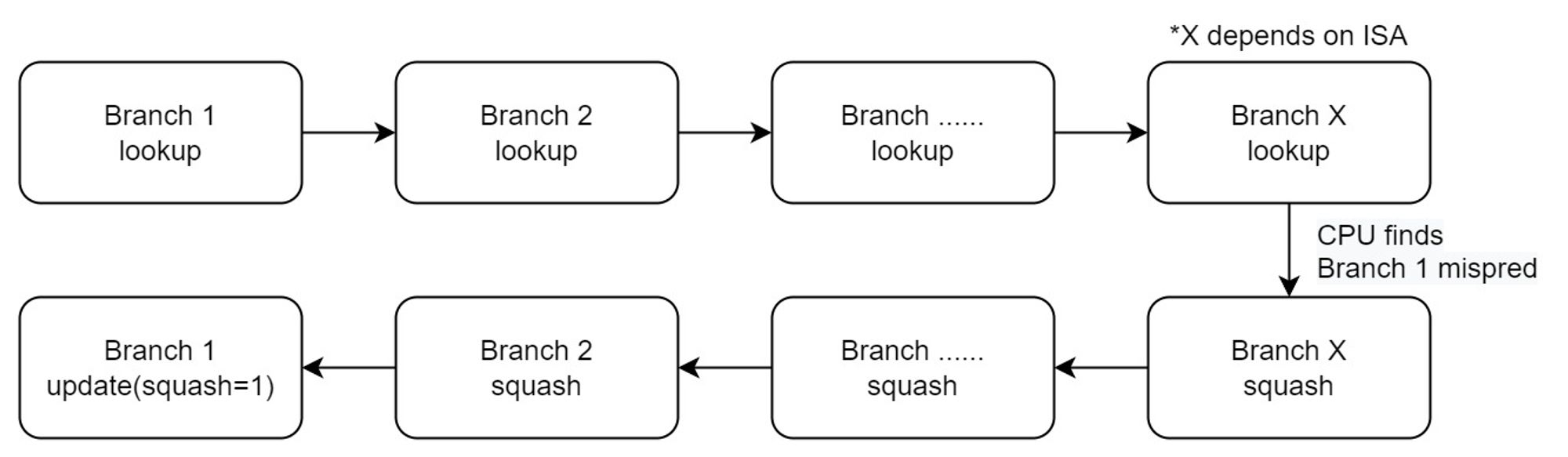
此时 gem5 会在同一个周期里,顺序对 Bx,B(x-1),…,B2 先调用
squash()。随后,还是在同一个周期内,再对 B1 调用 update(squash=true)。按照以上逻辑,squash 就应当只恢复这个分支的错误预测带来的后果,不考虑其它分支。由此我们就可以去实现任何分支预测器。
最后,添加模块的 SCons 编译脚本,在对应目录下的 SConscript 中注册一下添加的内容(或新建一个Sconscript)。以目前状态为例,在
gem5/src/cpu/pred/SConscript 里的SimObject('BranchPredictor.py', sim_objects=[…])的列表里追加'TemporalStreamBP',并且在文件最后加上Source('my_bp.cc') DebugFlag('MyBP')
回到
gem5根目录,现在来重新编译gem5。首先运行python3 util/style.py -m
并根据提示改代码风格。修改完成后,在 git 提交改动并且编译:
git add src/cpu && git commit -m "cpu: Added MyBP" && scons build/X86/gem5.opt -j 20
然后就可以用编译好的新版本运行测试了。记得在入口脚本里把CPU的BP更换掉:
system.cpu = DerivO3CPU(branchPred=MyBP())
./build/X86/gem5.opt ./configs/learning_gem5/part1/two_level_my_bp.py ./spectre
最后分享一个小脚本:
将其放在 gem5 根目录。每次用 gem5 运行完 testbench,在命令行执行:
python3 benchmark.py 即可查看本次运行 IPC、分支预测的准确率和 MPKI(Missing Per Kilo Instructions,BP 领域常用的指标)的情况。可能遇到的问题
Could not make proto path relative
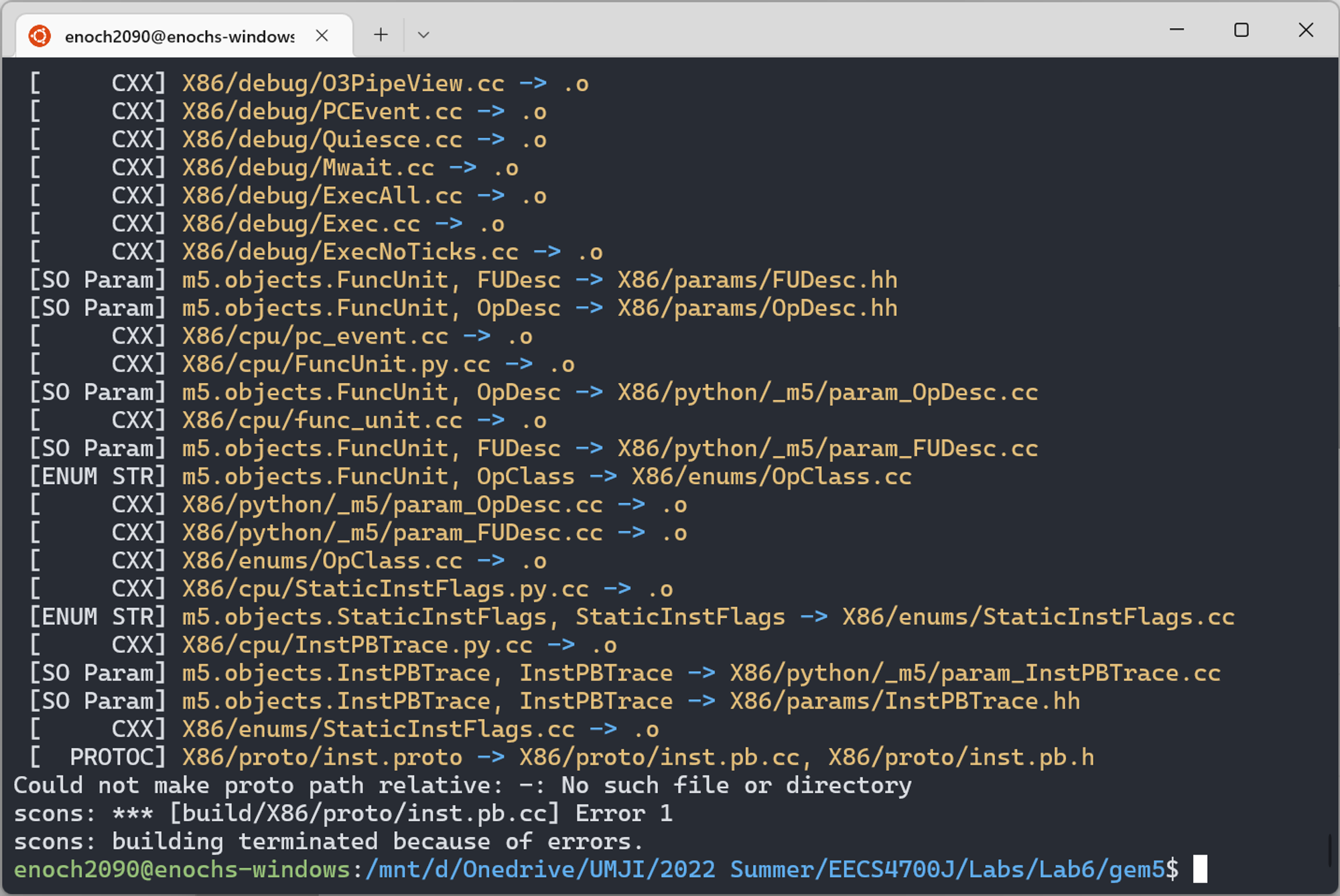
这种情况基本上都是由于路径名称不规范导致的,我猜测是
protobuf 对特殊字符的路径处理出错了。建议换个不带空格和特殊字符的路径。很多企业/学校账户的 OneDrive 文件夹会默认叫 OneDrive - COMPANY_NAME,放在那里面就会出这个问题。‘python3\r’: No such file or directory
CSDN上有一篇文章详细研究了这个报错的原因:

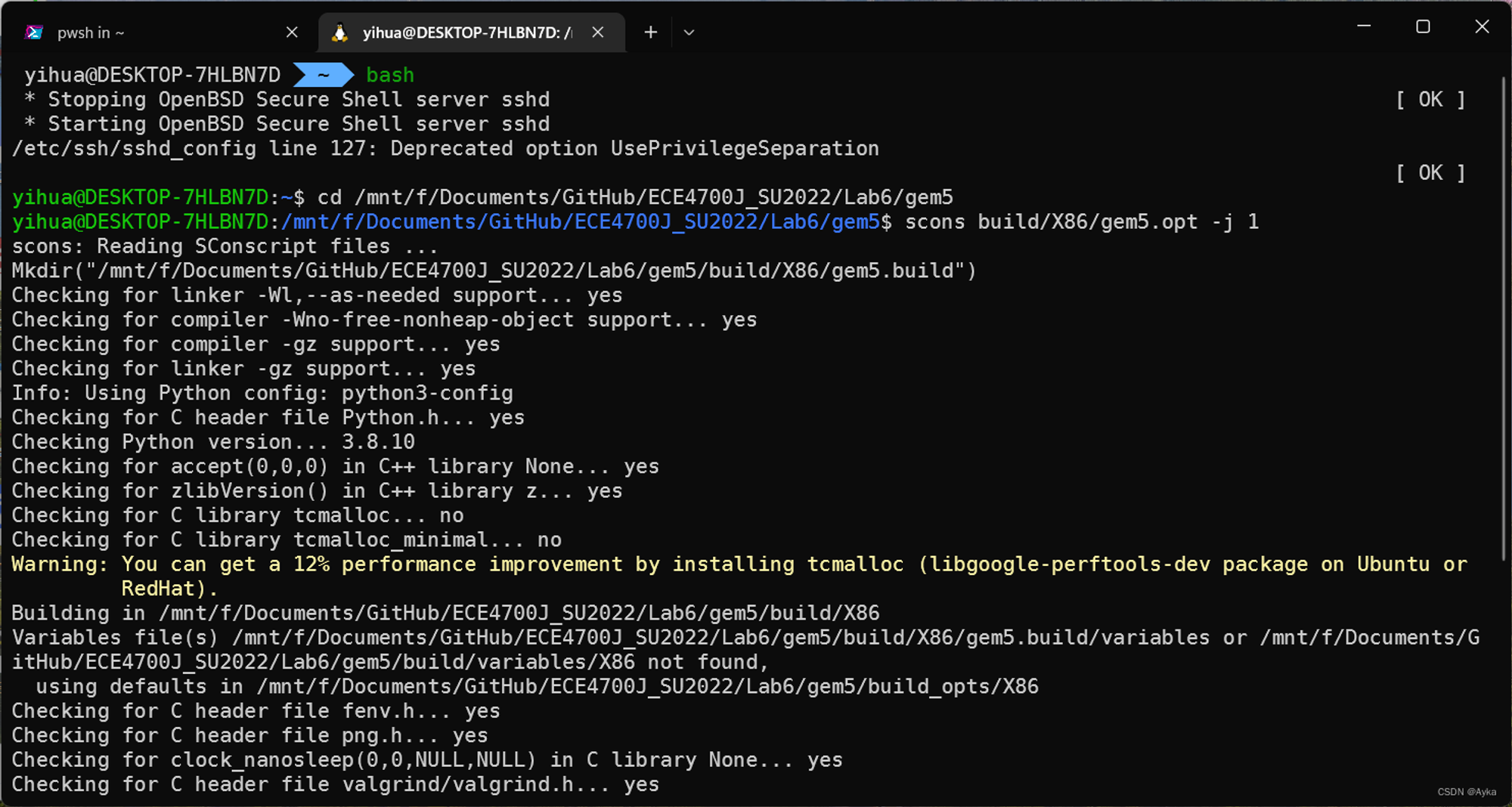
如果你感兴趣可以参考一下。但是其实不必这样仔细研究也能找到原因,因为这一看就是代码里多了个不该有的
\r,而代码本身是 git clone 下来的不应该有错,所以唯一可能出问题的地方就是操作系统。这是 Windows 默认使用的 CRLF 换行格式导致的,所以不要在 Windows 下面执行 git clone,到 wsl 里面执行即可。