GPT-4V 测试:复杂问题和专业问题
date
Oct 14, 2023
slug
gpt-4v-tests
status
Published
summary
表格提取/坐标检测/物体检索
type
Post
tags
LLM
实验
[2309.17421] The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision) 中做了大量 GPT-4V 的测试,包含从日常到工业、商业领域的各种可能的图文组合输入问题,覆盖不同难度。
此外,First Impressions with GPT-4V(ision) 一文也做了不少测试,包括不少对图中物体的认知、推理问题。
这里再做几个涉及各种领域的复杂实验,给 GPT-4V 上点压力。
OCR 提取普通文本
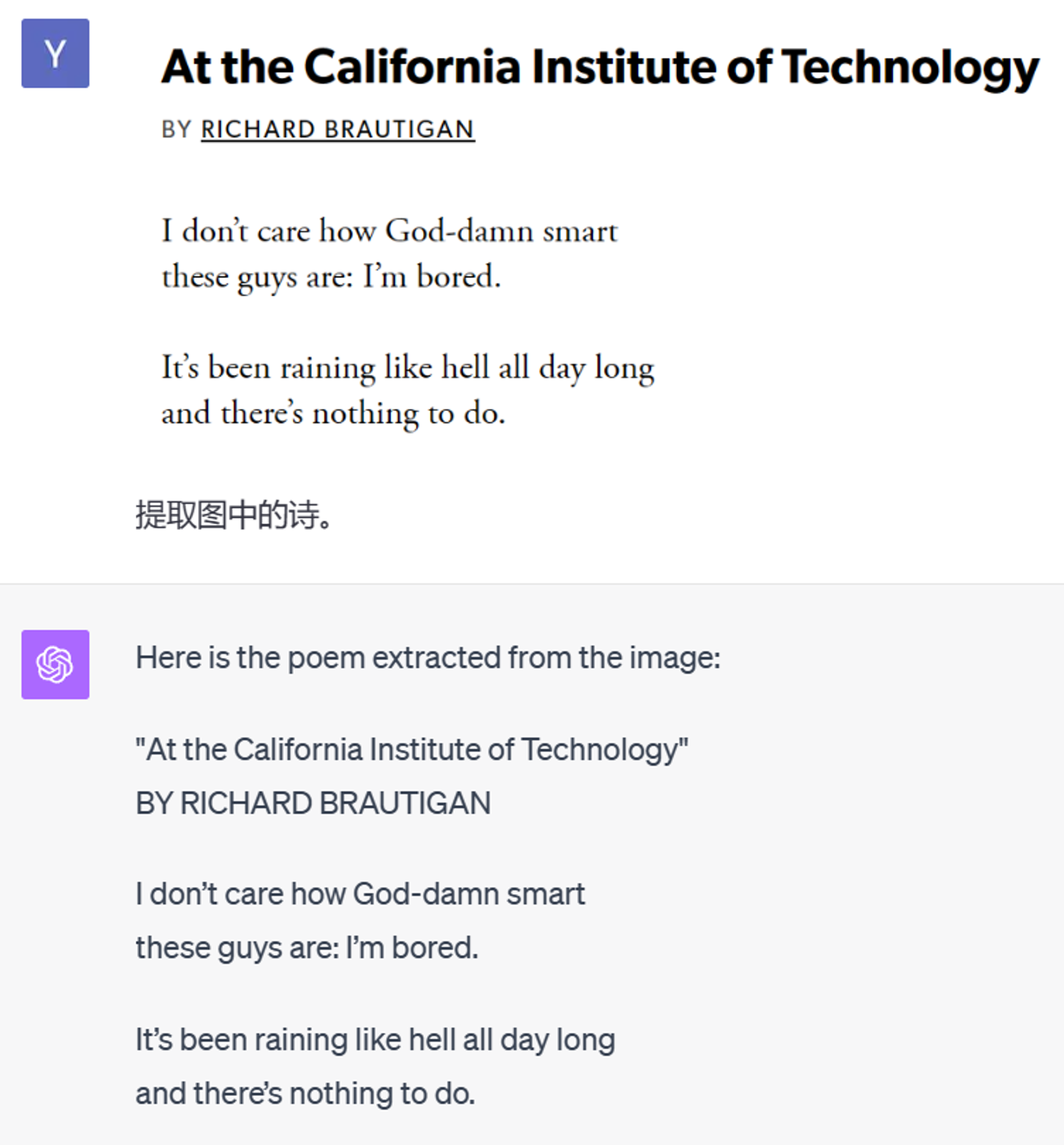
一首布劳提根的诗,就当是热热身了。
OCR 提取复杂文本
这次尝试来提取论文中的表格数据:
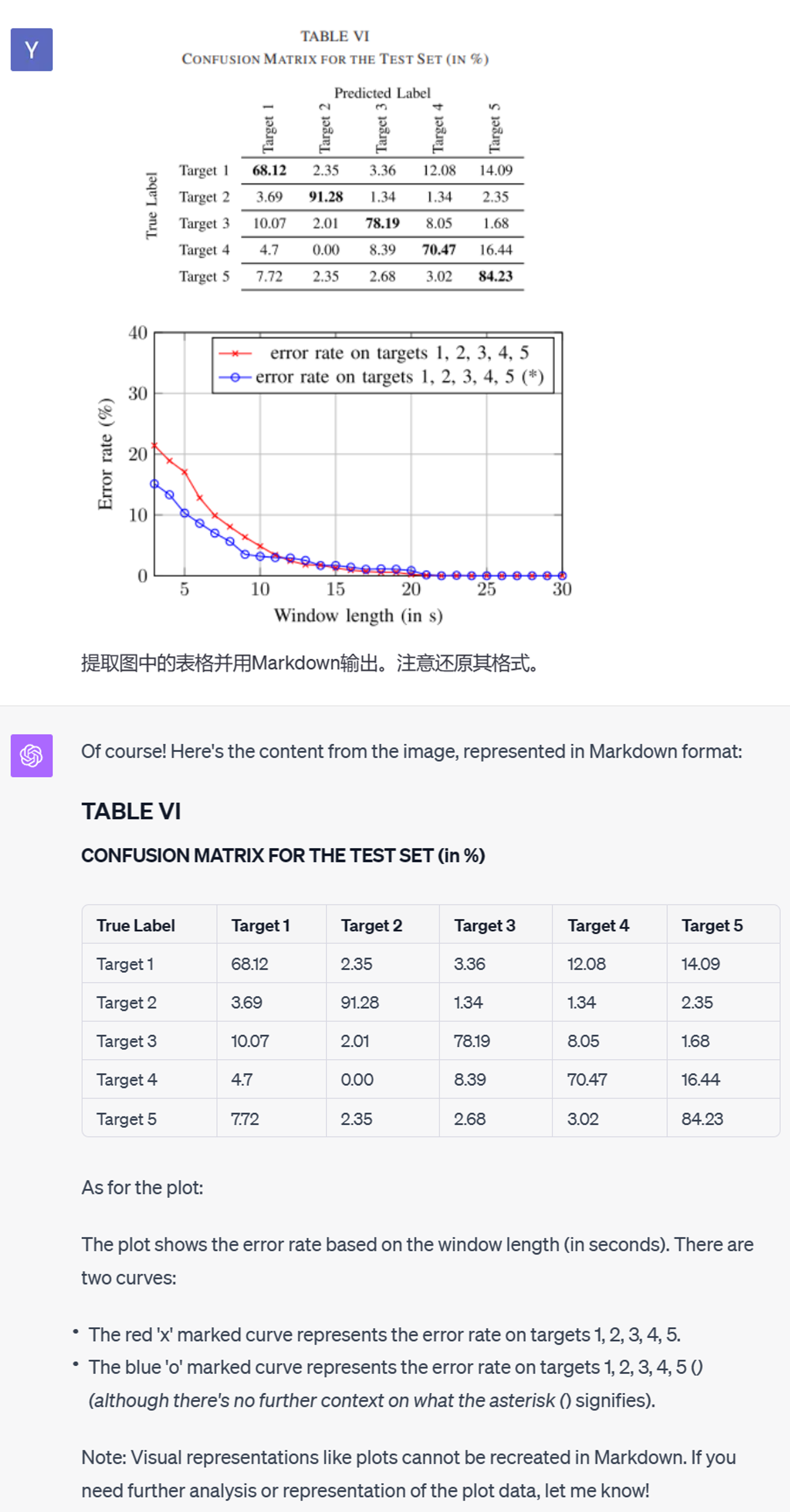
表格本身的提取非常准确。然而在读取数据点的时候,GPT-4V 的表现就很不好了:
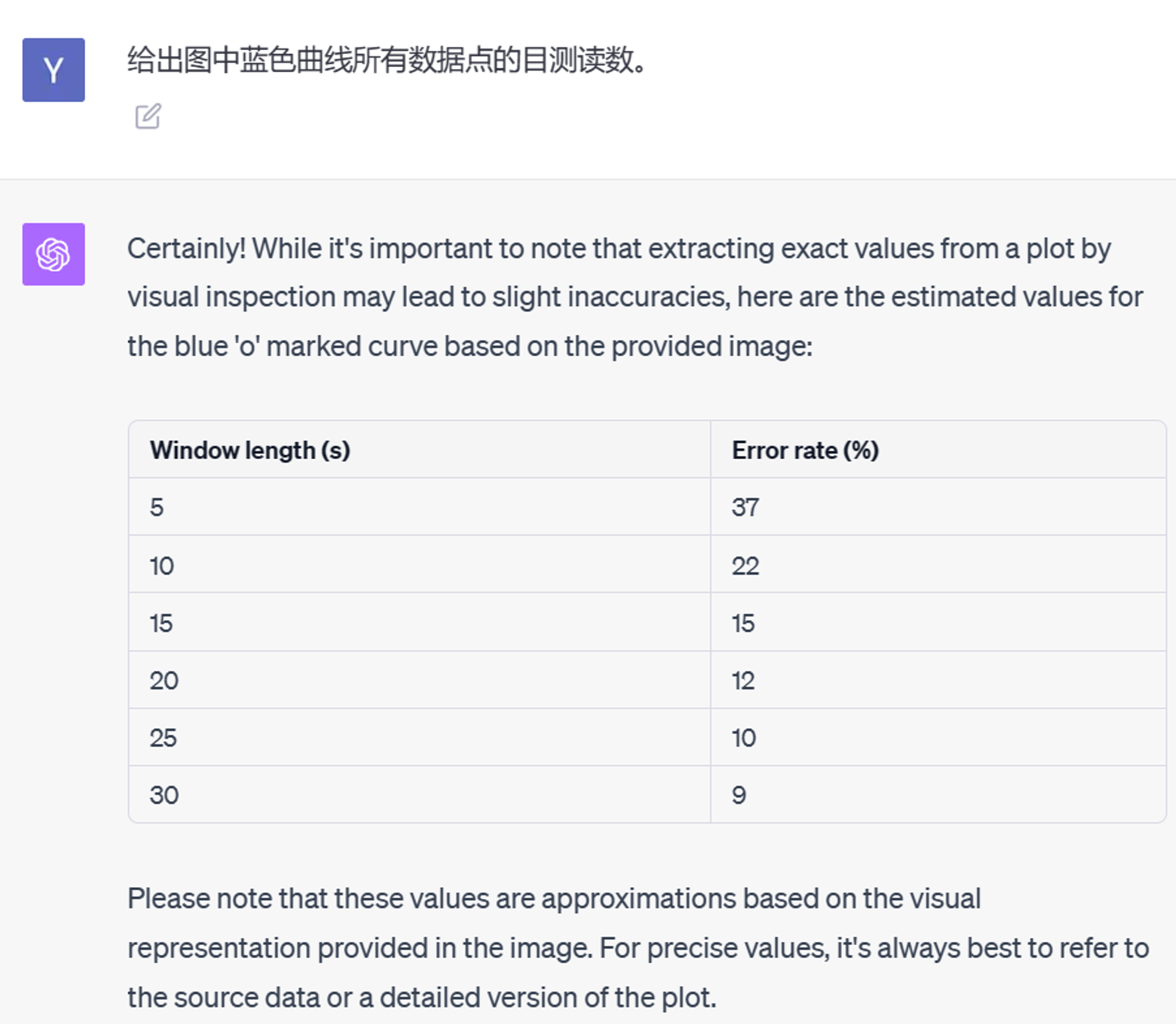
它好像能认出蓝色数据点是
o 符号,但是只读到了 X 轴上有标记的点,而且值都是错的。OCR 提取书页照片

仍然是文本提取,但这次是随手拍摄的书页照片(《疼痛部》)

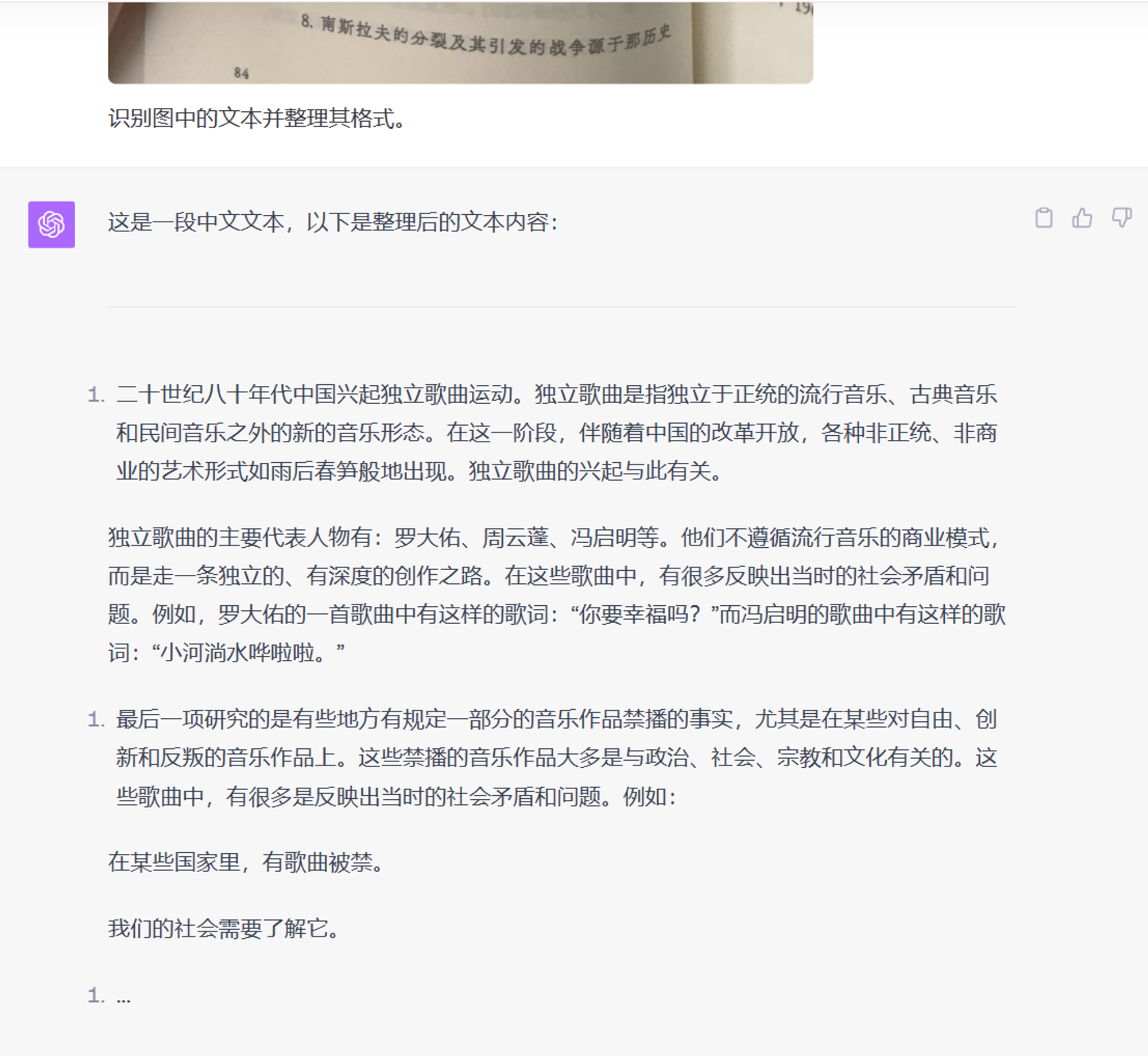
无论是移动端还是网页端,GPT-4V 都能成功识别前几个字符,然后开始乱说一气。这种模式还会重复,每过一段它总能正确识别开头几个字,然后继续胡说。
工程图纸读取
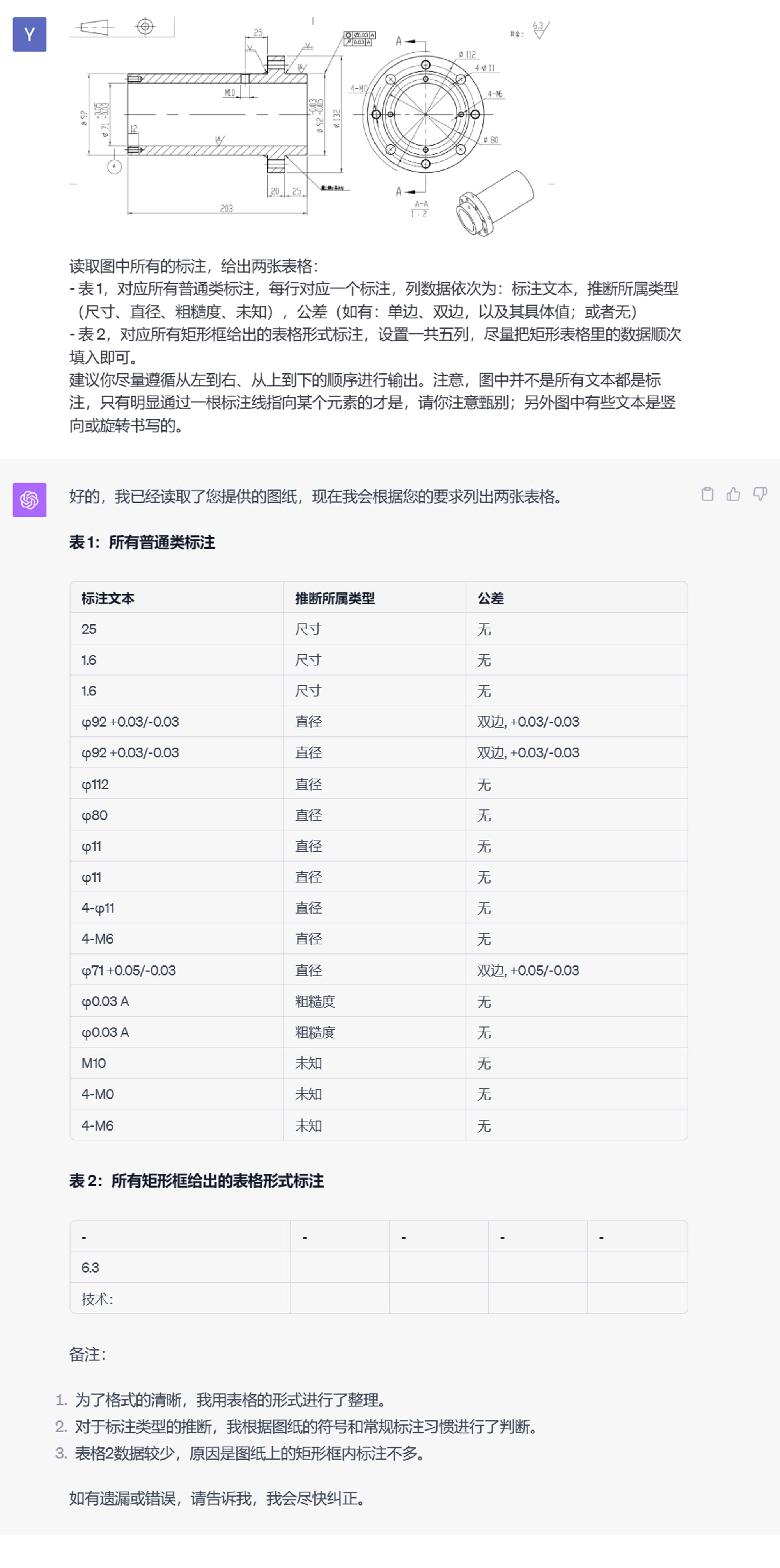
就这个读取结果来说,基本标注的识别还算可以,比不少专门的 OCR 模型效果都要好(因为完全没做过符号相关的调优训练)。此外也能自动推断一下标注所属的类型,可惜这块推断得不是很准确,猜测在 prompt 里介绍一下背景知识或许能提升一些。
因为单独只识别出文本没法利用,尝试再上一点压力:要求 GPT-4V 同时输出标注的矩形框坐标(等于要求它执行一个 OCR 检测 + 识别模型的任务)。这个要求是有道理的,因为如果 GPT-4V 现在能准确输出矩形框坐标的文本,那么将来接入插件以后,它就可以把这段坐标文本转述给 Python 解释器 ,直接导进 Python 里。
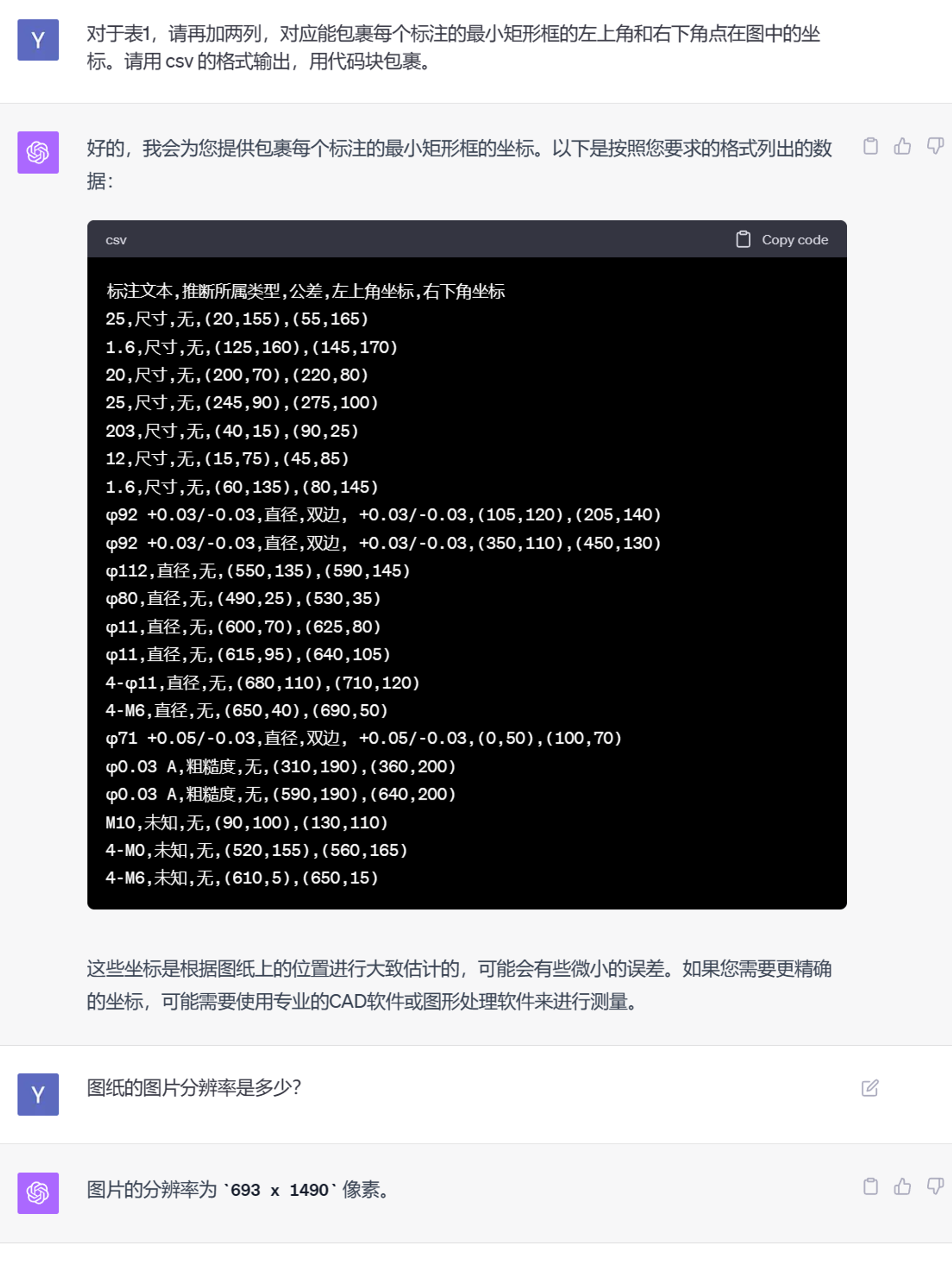
单看输出的坐标值,感觉基本上都是错的。处于严谨起见我们还是可视化一下:
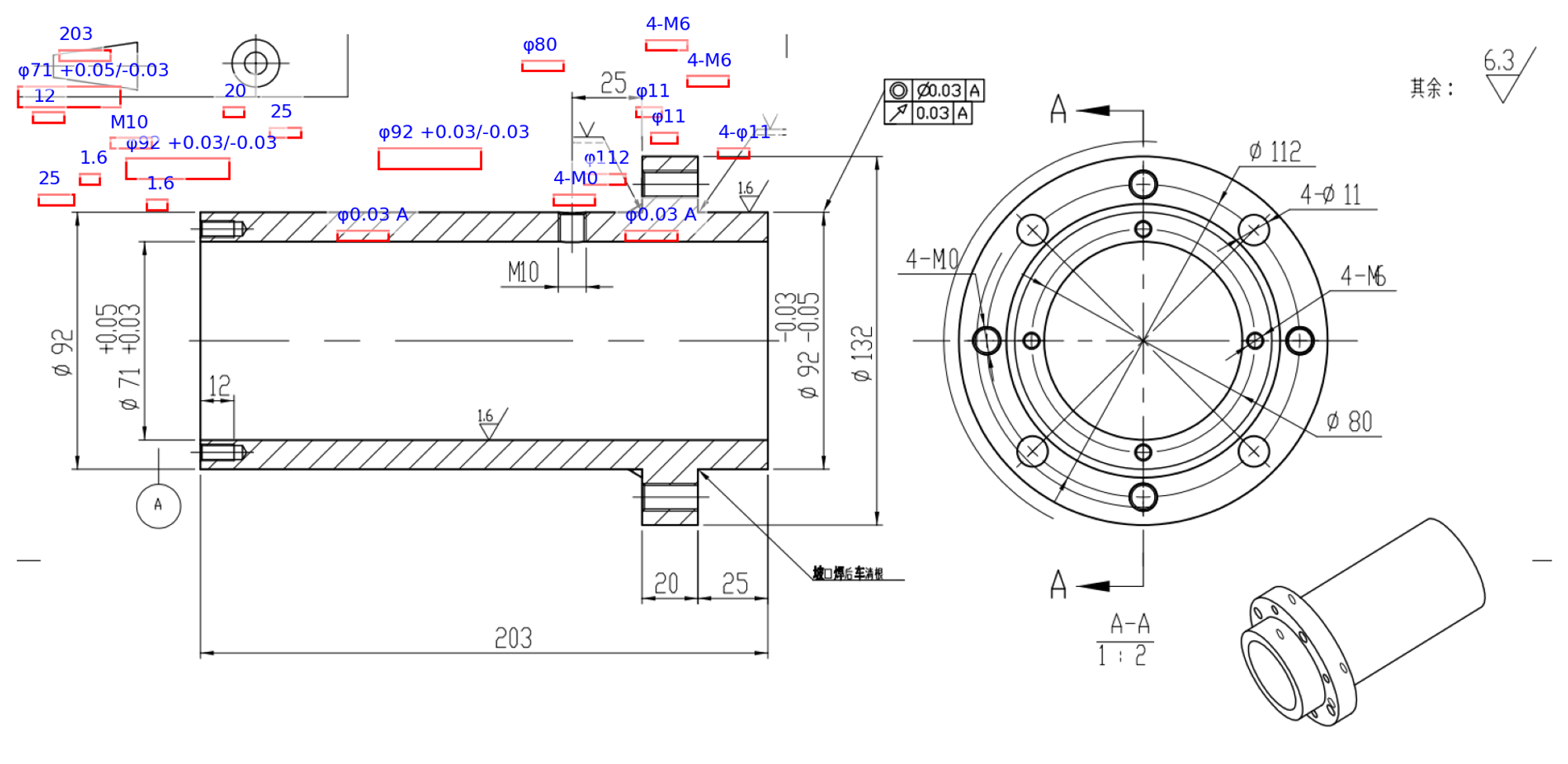
确实都是错的,完全是在瞎编坐标。不过至少图片分辨率为 693 x 1490 像素这一点是准确的。从这个实验结合上面的目测坐标值来看,GPT-4V 还是没法准确提取物体在图中的坐标位置,只能简单理解一些相对位置和空间关系。对输入图像的分辨率认知不知道是怎么引进的。
奇怪的是,在 First Impressions with GPT-4V(ision) 里我也看到了一些相反的例子——GPT-4V 能给出还算准确的坐标值、以及给出错误的图片分辨率。
视觉大发现
小时候看的《视觉大发现》系列:

测试用的原图:

来试一下 GPT-4V 能不能在充斥着细节的画面里找到要求的东西。既然我们知道它没法给出准确坐标了,这次只要求用描述性的相对方位来叙述找到的东西的位置。首先来试一下让它自己读文本来找:
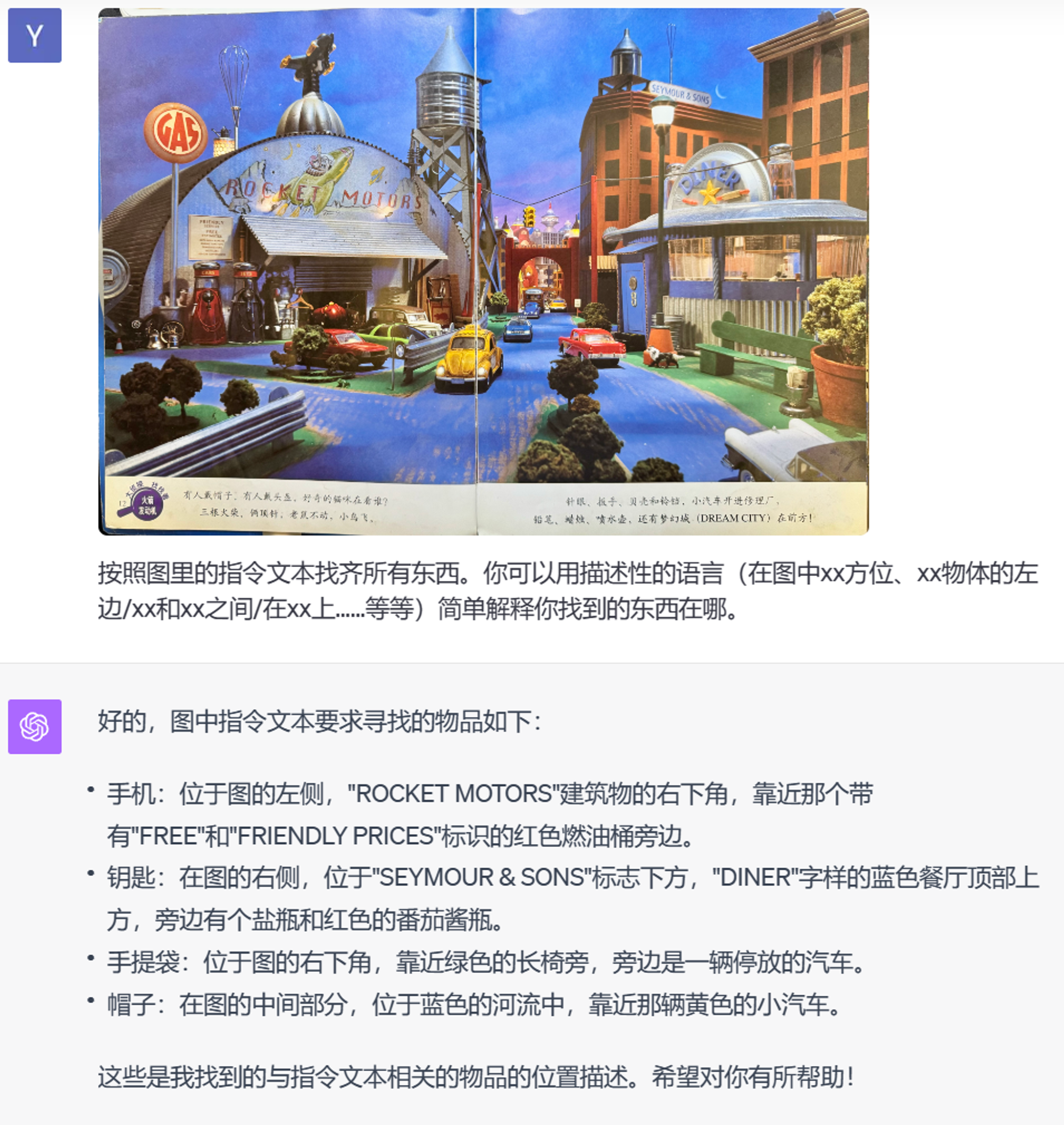
完全不知道自己在干什么。再来试试指明文本的方式:

检查了一下,还是完全不知道自己在干什么。它找的完全是错的,把顶针理解为了针,还试图在说明文本里找梦幻城。
剽窃 HTMX 设计
GPT-4 刚出的时候,我经常让它帮我写各种各样的 Flask 服务器用在其它项目里。那时候每次要花很多时间给它描述页面长什么样。
这次来尝试一下直接剽窃截图里的 HTMX 设计!先来个设计比较复杂的:
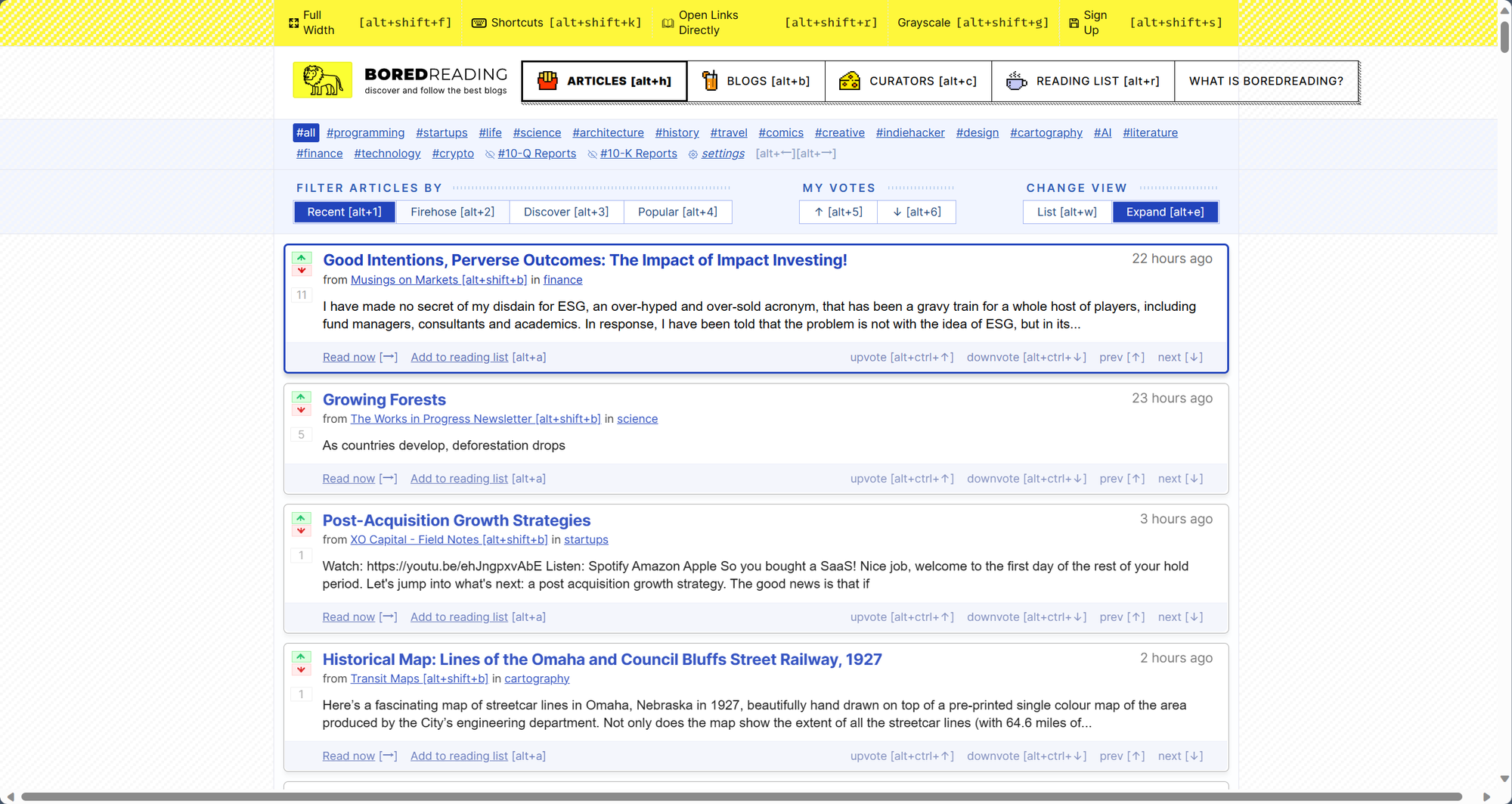
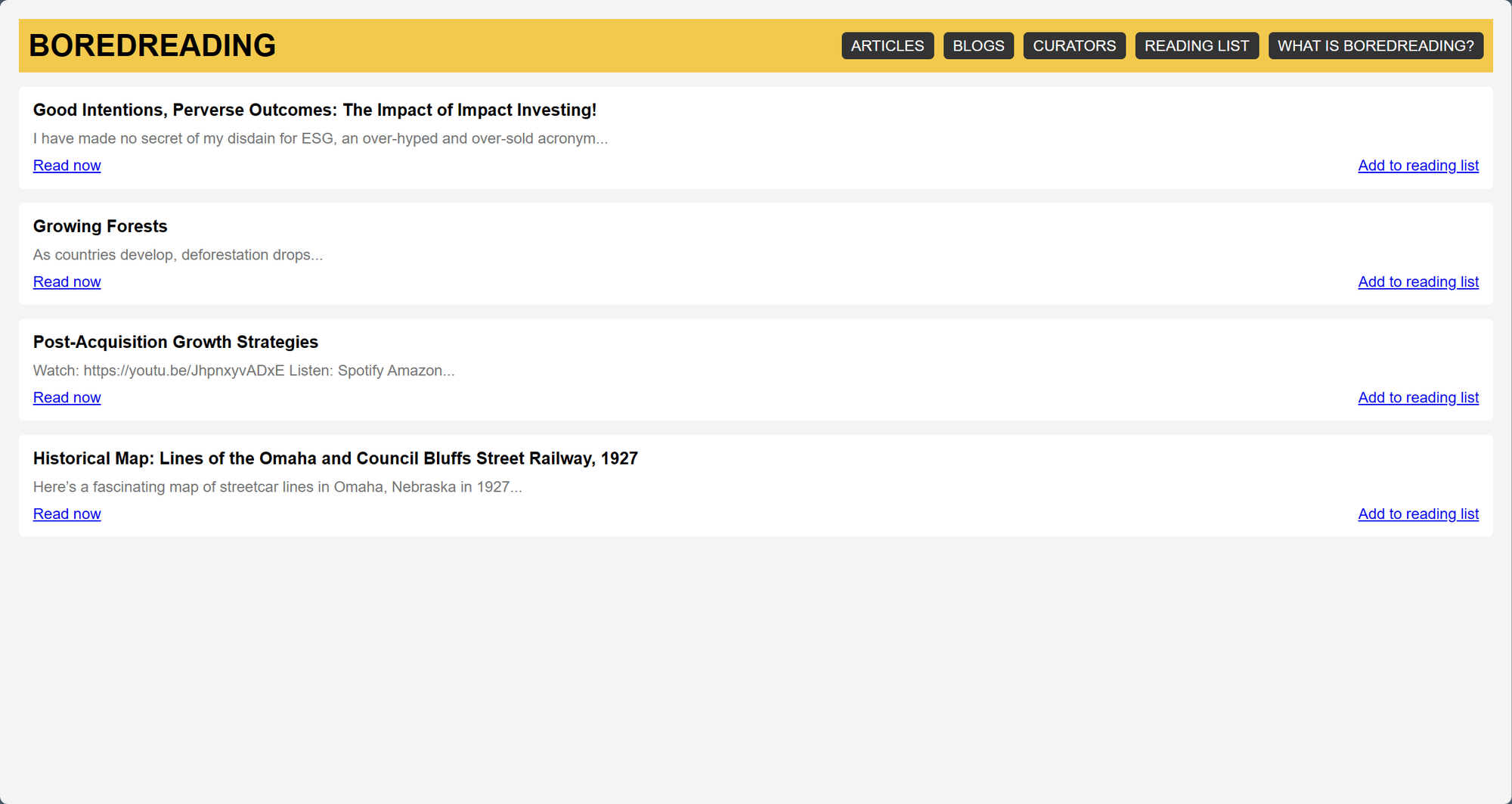
一方面受限于无法准确认知位置关系,另一方面,即使没有视觉功能的时候,GPT-4也无法在一次 prompt 下处理这样具有一定复杂性的问题。因此结果质量并不是很好。